总结11篇最近的研究论文,归纳三大类。
原标题:DeepSeek的多头潜在注意力(MLA)和11种KV-Cache技巧演进大总结
文章来源:智猩猩GenAI
内容字数:9138字
2025中国生成式AI大会预告及KV-Cache技术深度解析
2025中国生成式AI大会(北京站)即将于4月1日-2日举行,聚焦DeepSeek与大模型等前沿技术。本文将总结11篇最新研究论文,探讨KV-Cache如何优化大型语言模型(LLM)的文本生成速度。
1. 文本生成缓慢的原因:自注意力机制的计算瓶颈
大型语言模型的文本生成速度慢,主要源于自注意力机制。在生成每个新token时,模型需要重新计算所有先前token的上下文信息,计算成本随序列长度呈平方增长(O(n²))。
2. KV缓存:巧妙的权衡
KV缓存通过预计算并存储每个token的键(key)和值(value)来解决这个问题。生成新token时,只需查找相关信息,将计算复杂度降低到线性(O(n))。但与此同时,KV缓存也增加了内存消耗。
3. 优化KV缓存的三大方法
为了解决KV缓存的内存问题,研究人员提出了三大类优化方法:
3.1 Token选择和修剪方法
1. Heavy-Hitter Oracle (H2O+):识别并保留重要token,减少缓存大小。
2. StreamLLM+:利用注意力汇聚现象,保留初始token,处理最近上下文。
3. Value-Aware Token Pruning (VATP):综合考虑注意力分数和值向量信息,进行token修剪。
3.2 后处理压缩技术
4. Adaptive KV Compression (FastGen):根据运行时注意力模式自适应地选择压缩策略。
5. 动态内存压缩 (DMC+):自适应地合并token,降低内存占用。
6. 范数基础的压缩:利用键嵌入范数与注意力分数的相关性进行压缩。
3.3 体系结构重设计
7. 多查询注意力 (MQA+):共享键值头,减少缓存大小。
8. 分组查询注意力 (GQA+):在MQA和传统多头注意力之间权衡。
9. 多头潜在注意力 (MLA):使用低秩潜在压缩技术,减少KV缓存大小。
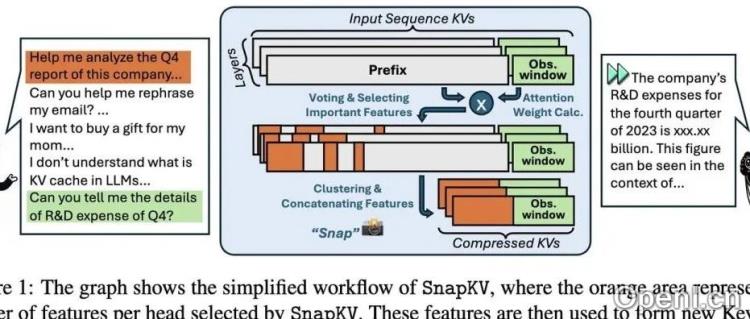
10. SnapKV:利用观察窗口识别注意力模式进行压缩。
11. 只缓存一次 (YOCO):修改Transformer架构,优化缓存机制。
4. 结论
KV-Cache技术是优化LLM推理速度的关键。通过token选择、后处理压缩和架构重设计等方法,研究人员不断提升LLM的效率,使其在长上下文和资源受限的场景下也能良好运行。 KV-Cache仍然是一个活跃的研究领域,未来将有更多创新涌现。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。