PRefLexOR – MIT 团队推出的新型自学习AI框架
PRefLexOR是什么
PRefLexOR(Preference-based Recursive Language Modeling for Exploratory Optimization of Reasoning)是由麻省理工学院团队研发的一种先进自学习人工智能框架。该框架融合了偏好优化和强化学习(RL)的理念,通过迭代推理的方式提升自我学习的能力。PRefLexOR的核心在于其递归推理算法,模型在训练和推理的过程中会进行多轮推理、反思和优化,从而最终生成更为准确的结果。该框架建立在优势比偏好优化(ORPO)的基础上,模型通过优化偏好与非偏好响应之间的对数几率来协调推理路径,并结合直接偏好优化(DPO),通过拒绝采样进一步提升推理的质量。
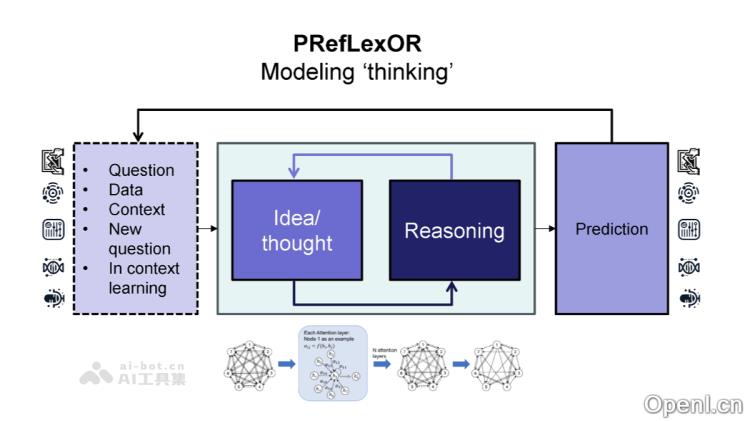
PRefLexOR的主要功能
- 动态知识图谱构建:该框架无需依赖于预先生成的数据集,而是通过实时生成任务和推理步骤来构建知识图谱,使模型能够持续适应新任务,并在推理过程中动态扩展其知识库。
- 跨领域推理能力:PRefLexOR具备整合不同领域知识的能力。例如,在材料科学领域,模型通过递归推理和知识图谱能够生成新的设计原则。
- 自主学习与进化:PRefLexOR运用递归优化和实时反馈机制,能够在训练过程中实现自我教学,持续改进推理策略,展现出类似人类的深度思考与自主发展的能力。
PRefLexOR的技术原理
- 递归推理与反思:PRefLexOR通过引入“思考令牌”和“反思令牌”,明确区分推理过程中的各个阶段。模型在推理时会首先生成初步响应,然后通过反思逐步改进,最终得出更精确的答案。
- 偏好优化:PRefLexOR基于优势比偏好优化(ORPO)和直接偏好优化(DPO)。模型通过优化偏好响应与非偏好响应之间的对数优势比来使推理路径与人类的决策过程保持一致。同时,DPO通过拒绝采样进一步调整推理质量,确保偏好对齐的细微差异。
- 多阶段训练:PRefLexOR的训练过程分为多个阶段,首先通过ORPO对齐推理路径,然后利用DPO进一步优化推理质量。这种混合方法类似于强化学习中的策略细化,模型通过实时反馈和递归处理不断改进。
PRefLexOR的项目地址
- Github仓库:https://github.com/lamm-mit/PRefLexOR
- arXiv技术论文:https://arxiv.org/pdf/2410.12375
PRefLexOR的应用场景
- 材料科学与设计:在材料科学领域,PRefLexOR展现出强大的推理能力。通过动态生成问题和检索增强技术(RAG),该模型能够从随机文本中提取信息,构建实时更新的知识图谱。
- 跨领域推理:PRefLexOR能够将不同领域的知识进行整合,进行跨领域的推理与决策。在生物材料科学中,模型可通过递归推理与反思机制,将生物学原理与材料科学结合,提出新的解决方案。
- 开放域问题解决:作为基于强化学习的自学习系统,PRefLexOR能有效应对开放域问题,通过迭代优化与反馈驱动的学习,不断提升其推理路径。
- 生成材料信息学:PRefLexOR可以用于生成材料信息学的工作流程,将信息转变为知识与可执行的结果。通过多步推理和自我评估,该模型能够实现更复杂的预测,支持材料预测的持续改进。
常见问题
- PRefLexOR的优势是什么?:PRefLexOR通过动态推理和自我学习能力,能够在不断变化的任务环境中快速适应并产生高质量的输出。
- 如何访问PRefLexOR?:用户可以通过项目官网和GitHub仓库获取更多信息和使用指导。
- PRefLexOR适用于哪些领域?:PRefLexOR适用于多个领域,包括材料科学、跨领域推理及开放域问题解决等。
- 使用PRefLexOR需要哪些技术背景?:虽然PRefLexOR设计为用户友好,具备基本编程知识和对人工智能的理解将有助于更好地利用该框架。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。