混元图生视频 – 腾讯混元开源的图生视频模型
混元图生视频是什么
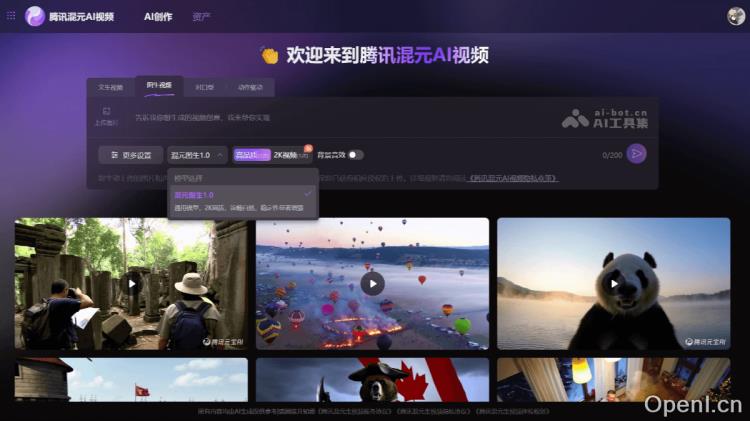
混元图生视频是由腾讯混元团队推出的一款开源图像生成视频模型。用户只需上传一张图片并简要描述,即可生成一段时长为5秒的动态视频。该模型具备自动化口型匹配、动作驱动和背景音效生成等多种功能,能够应用于写实、动漫及CGI等不同类型的角色和场景,拥有130亿的参数量。混元图生视频模型现已在腾讯云上线,用户可以通过混元AI视频官网进行体验。此外,该模型已在GitHub和HuggingFace等开发者社区开源,提供了权重、推理代码及LoRA训练代码,开发者可基于此进行专属LoRA等衍生模型的训练。

混元图生视频的主要功能
- 图像生成视频:用户可以通过上传一张图片并提供简短描述,模型能够将静态图像转化为5秒的短视频,并且支持自动生成背景音效。
- 音频驱动功能:用户上传人物图片后,可以输入文本或音频,模型将准确匹配嘴型,使图片中的人物能够“说话”或“唱歌”,并展现相应的面部表情。
- 动作驱动功能:用户上传图片后,选择动作模板,模型能够让图片中的人物完成跳舞、挥手、做体操等动作,适用于短视频创作、游戏角色动画及影视制作。
- 高质量视频输出:支持2K高清画质,适合多种角色与场景,包括写实、动漫及CGI。
混元图生视频的技术原理
- 图像到视频生成框架:HunyuanVideo-I2V通过图像潜在拼接技术,将参考图像的信息整合到视频生成过程中。输入图像经过预训练的多模态大型语言模型(MLLM)处理,生成语义图像token,并与视频潜在token拼接,以实现跨模态的全注意力计算。
- 多模态大型语言模型(MLLM):该模型采用Decoder-only结构的MLLM作为文本编码器,显著增强了对输入图像语义内容的理解能力。与传统的CLIP或T5模型相比,MLLM在图像细节描述和复杂推理方面表现更佳,能够更好地实现图像与文本描述的深度融合。
- 3D变分自编码器(3D VAE):为高效处理视频和图像数据,HunyuanVideo-I2V使用CausalConv3D技术训练了一个3D VAE,将像素空间中的视频和图像压缩到紧凑的潜在空间。这种设计显著减少了后续模型中的token数量,能够在原始分辨率和帧率下进行训练。
- 双流转单流的混合模型设计:在双流阶段,视频和文本token通过多个Transformer块处理,避免相互干扰;在单流阶段,将视频和文本token连接起来,进行多模态信息融合。这种设计捕捉了视觉和语义信息之间的复杂交互,提升了生成视频的连贯性和语义一致性。
- 渐进式训练策略:模型采用渐进式训练策略,从低分辨率、短视频逐步过渡到高分辨率、长视频,提高了模型的收敛速度,确保了生成视频在不同分辨率下的高质量。
- 提示词重写模型:为解决用户提示词的语言风格和长度多变性问题,HunyuanVideo-I2V引入了提示词重写模块,能够将用户输入的提示词转换为模型更易理解的格式,提高生成效果。
- 可定制化LoRA训练:模型支持LoRA(Low-Rank Adaptation)训练,开发者可以通过少量数据训练出具有特定效果的视频生成模型,例如“头发生长”或“人物动作”等特效。
产品官网
- Github仓库: https://github.com/Tencent/HunyuanVideo-I2V
- Huggingface模型库:https://huggingface.co/tencent/HunyuanVideo-I2V
- 混元AI视频官网:腾讯混元AI视频官网
混元图生视频的应用场景
- 创意视频生成:用户可以通过上传图片和描述生成富有创意的短视频。
- 特效制作:通过LoRA训练实现个性化特效,如头发生长、人物动作等。
- 动画与游戏开发:快速生成角色动画,降作成本,提高开发效率。
常见问题
- 如何使用混元图生视频?用户可以访问腾讯混元AI视频官网,选择图生视频,上传一张图片并输入简短描述即可生成短视频。
- 对开发者的支持有哪些?开发者可以通过腾讯云申请API接口,或在GitHub上下载开源模型进行本地部署和定制化开发。
- 硬件要求是什么?最低要求为NVIDIA显卡,支持CUDA,显存至少60GB(生成720p视频),推荐80GB显存,操作系统需为Linux。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。