WeGen – 中科大联合上海交大等推出的统一多模态生成模型
WeGen是什么
WeGen是由中国科学技术大合上海交通大学、微信团队及中国科学院等多家机构研发的一个综合性多模态生成模型,旨在通过自然对话实现丰富的视觉生成任务。该模型结合了多模态大语言模型(MLLM)与扩散模型,能够高效处理文本到图像生成、条件生成、图像编辑、风格迁移等多种类型的任务。WeGen的显著优势在于,当用户的指令较为模糊时,它可以提供多样化的创意输出;而在用户有具体需求时,确保生成的结果与指令及参考图像的一致性。通过动态实例一致性(DIIC)数据管道与提示自重写(PSR)机制,WeGen有效解决了实例身份一致性与生成多样性这两大挑战,展现出作为设计助手的巨大潜力。
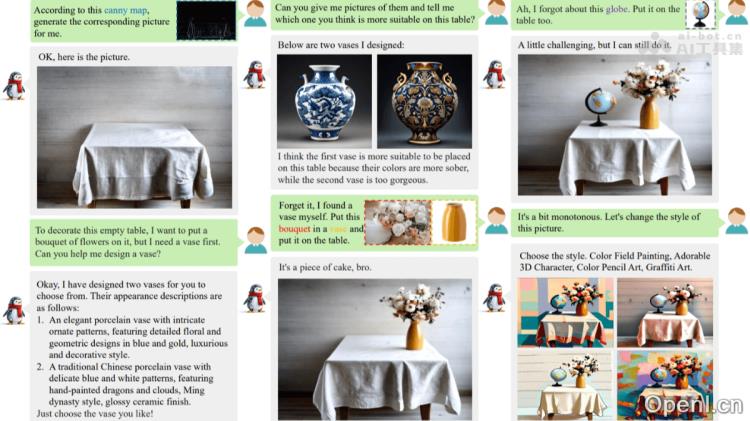
WeGen的主要功能
- 文本到图像生成:根据用户的文本描述生成高质量的图像。
- 条件驱动生成:依据特定条件(如边缘图、深度图、姿态图)进行图像生成。
- 图像编辑与修复:对已有图像进行修改、修复或扩展。
- 风格迁移:将一种图像的艺术风格应用到另一张图像上。
- 多主体生成:在生成的图像中保留多个参考对象的重要特征。
- 交互式生成:通过自然对话与用户互动,逐步优化生成结果。
- 创意设计辅助:为用户提供多样的生成选项,激发创意灵感。
WeGen的技术原理
- 多模态大语言模型(MLLM)与扩散模型结合:利用CLIP作为视觉编码器,将图像转化为语义特征,并使用扩散模型(如SDXL)作为解码器,生成高质量的视觉内容,LLM(如LLaMA)则处理自然语言指令,实现文本与视觉信息的有效融合。
- 动态实例一致性(DIIC):通过视频序列跟踪对象的自然变化,确保对象身份的一致性。DIIC数据管道克服了传统方法在实例身份保持中的不足,使模型在修改图像时保留关键特征。
- 提示自重写(PSR)机制:基于语言模型对文本提示进行重写,引入随机性,从而生成多样化的图像。PSR通过离散文本采样,使模型能够探索不同的解释,同时保持语义的一致性。
- 统一框架与交互式生成:WeGen将多种视觉生成任务整合在一个框架内,基于自然对话与用户互动,逐步优化生成结果,确保保留用户所满意的部分。
- 大规模数据集支持:WeGen通过从互联网视频提取的大规模数据集进行训练,数据集包含丰富的对象动态和自动标注的描述,帮助模型学习保持一致性和生成多样性。
WeGen的项目地址
- GitHub仓库:https://github.com/hzphzp/WeGen
- arXiv技术论文:https://arxiv.org/pdf/2503.01115
WeGen的应用场景
- 创意设计:帮助设计师快速生成创意概念图,激发灵感,适用于广告、包装、建筑等多个领域。
- 内容创作:为影视、游戏、动漫等行业提供场景、角色或道具的概念图,加速创作流程。
- 教育辅助:生成与教学内容相关的图像,帮助学生更直观地理解抽象概念。
- 个性化定制:根据用户需求生成定制化的设计方案,如服装、家居装饰等。
- 虚拟社交与娱乐:生成虚拟形象、场景或道具,增强虚拟社交和游戏的沉浸感。
常见问题
- WeGen支持哪些语言? WeGen支持多种语言的文本输入,能够处理多语种的自然对话。
- 如何获取WeGen? 用户可以通过访问GitHub仓库下载WeGen,并查看相关文档以获取使用指南。
- WeGen生成的图像质量如何? WeGen采用先进的扩散模型,生成的图像质量高,能够满足大多数设计需求。
- WeGen是否免费? WeGen的开源版本可以免费使用,但具体的商业使用可能需要遵循相关的许可证。
- 如何反馈使用体验? 用户可以在GitHub仓库中提交问题或建议,与开发者进行互动。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。