DINO-XSeek – IDEA 研究院推出的多模态目标检测模型
DINO-XSeek是什么
DINO-XSeek是由IDEA研究院开发的一款多模态目标检测模型,融合了视觉识别与自然语言处理的能力。该模型能够根据复杂的语言描述,精准定位图像中的目标,并识别其属性(如颜色、形状、动作等)、空间关系及交互情况。DINO-XSeek基于DINO-X统一视觉模型,通过检索式框架,首先检测图像中的所有物体,然后利用大型语言模型从候选目标中筛选出最相关的对象。该技术在自动驾驶、工业制造、智能家居、农业与食品等多个领域得到了广泛应用,能够实现安全检测、质量控制、危险行为识别等功能,为复杂场景的目标检测提供了接近人类理解能力的解决方案。
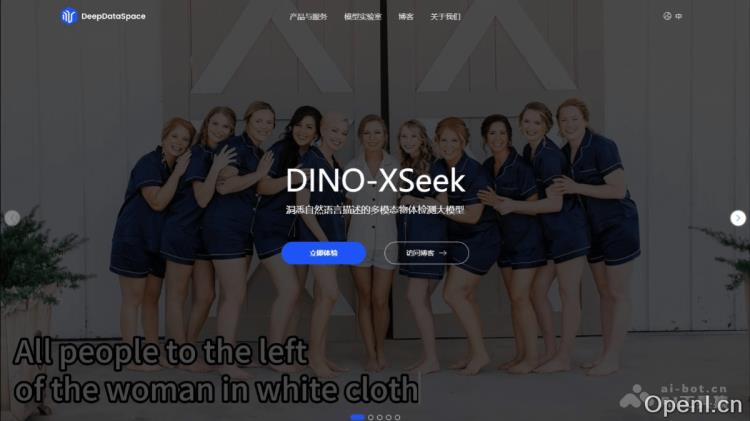
DINO-XSeek的主要功能
- 复杂语言理解:根据自然语言描述精准定位图像中的目标,支持对目标的详细描述,如“穿着红色上衣的女孩”或“站在汽车旁的人”。
- 属性识别:能够识别目标的颜色、形状、年龄、性别、服饰、姿势和动作等属性。
- 位置与空间关系识别:支持判断目标之间的相对位置以及目标与周围环境的空间关系。
- 交互关系识别:识别目标之间以及目标与环境之间的互动关系。
- 推理与多实例处理:支持复杂的语言推理,能够处理多实例指代任务。
DINO-XSeek的技术原理
- 视觉编码器:提取图像中的视觉信息,生成视觉token,用于描述图像中的物体和场景。
- 目标检测模型(DINO-X):基于开放集目标检测模型,检测图像中的所有物体,并生成候选目标的边界框。
- 文本tokenizer:将自然语言描述转换为文本token,提取语言中的语义信息。
- 检索式框架:将视觉token、物体token和文本token一同输入到大型语言模型(LLM)中,基于语言模型的推理能力,从候选目标中检索出与语言描述最匹配的对象,而不是直接预测坐标。
- 多模态融合与推理:结合视觉与语言模态,理解复杂的语言描述,通过语言模型的推理能力,精准定位目标,实现指代表达理解(Referring Expression Comprehension,REC)。
DINO-XSeek的项目地址
DINO-XSeek的应用场景
- 自动驾驶:识别道路、交通标志、障碍物等,辅助自动驾驶决策,提升行车安全。
- 工业制造:检测零部件缺陷,识别未遵守安全规范的人员,保障生产质量和安全。
- 智能家居与生活:识别家庭中的危险行为(如老人摔倒),提供智能设备交互支持。
- 农业与食品:检测农作物病虫害和食品缺陷,提升种植与生产效率。
- 安防监控:识别异常行为及目标,实时预警,增强监控系统的效能。
常见问题
- 1. DINO-XSeek支持哪种语言描述? DINO-XSeek支持多种自然语言描述,能够解析复杂的指代和描述性语言。
- 2. DINO-XSeek的主要应用领域有哪些? 主要应用于自动驾驶、工业制造、智能家居、农业与食品及安防监控等领域。
- 3. DINO-XSeek如何处理复杂的目标识别任务? 通过结合视觉信息和自然语言描述,DINO-XSeek能够精准定位和识别多种目标。
- 4. DINO-XSeek的技术优势是什么? DINO-XSeek利用先进的视觉编码和语言模型技术,实现了更高效、更精确的目标检测和识别。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。