Qwen2.5-Coder 是由阿里 Qwen 团队推出的一款全新代码生成模型系列,致力于推动开源代码语言模型的发展。该产品在代码生成、推理和修复等方面展现出色性能,涵盖从 0.5B 到 32B 的六种不同规模的模型,旨在满足各类开发者的多样化需求。
Qwen2.5-Coder是什么
Qwen2.5-Coder 是阿里 Qwen 团队推出的全面代码生成模型系列,旨在推动开源代码语言模型的发展。该系列在代码生成、推理及修复等任务中表现优异,涵盖了多种规模的模型,包括 0.5B、1.5B、3B、7B、14B 和 32B,满足不同开发者的需求。
其旗舰模型 Qwen2.5-Coder-32B-Instruct 在多个主流代码生成基准测试中表现突出,与 GPT-4o 相当,展现出强大的代码生成、修复及推理能力,支持超过 40 种编程语言,并在 McEval 和 MdEval 基准中取得了显著成绩。
Qwen2.5-Coder 强调人与模型的偏好对齐,经过内部评估基准 Code Arena 的评估,显示出其在人类偏好上的优势。模型家族的参数配置和许可证信息也一一列出,其中 0.5B、1.5B、7B、14B 和 32B 模型采用 Apache 2.0 许可证,而 3B 模型则使用研究用途的许可证。
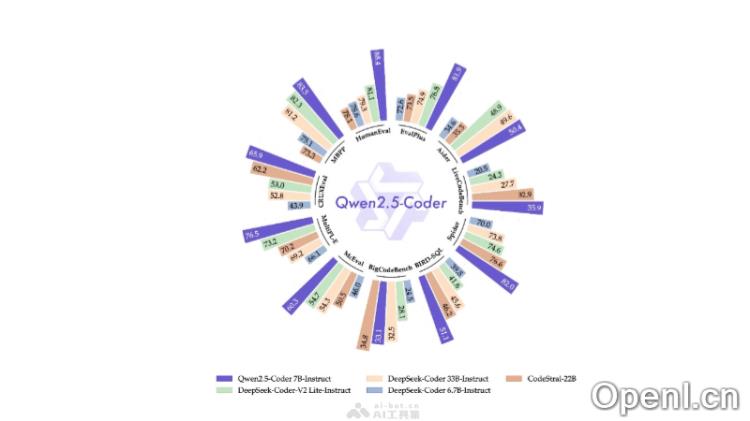
Qwen2.5-Coder的主要功能
- 代码生成:根据输入的编程提示,Qwen2.5-Coder 能够生成相关的代码片段,支持多种编程语言。
- 代码推理:具备强大的代码推理能力,能够理解代码逻辑并提供相关建议。
- 代码修复:帮助开发者识别并修复代码中的错误。
- 多语言支持:支持多达 92 种编程语言,包括流行的 Python、Java 和 C++ 以及其他小众语言。
- 模型尺寸多样性:提供从 0.5B 到 32B 的六种主流模型尺寸,满足不同开发者的需求。
- 指令调优:通过指令微调提升了多项任务的性能。
- 数学能力:在代码和数学任务上表现优异,将编程与数学能力相结合。
Qwen2.5-Coder的技术原理
- 自回归语言模型:采用自回归机制,根据已有文本序列预测下一个最可能的 token,使得文本生成与补全任务表现出色。
- 模型架构:基于 Qwen2.5 架构,使用 Transformer 模型变种,提供不同参数规模的选择,如 1.5B、7B 和 32B,参数配置包括隐藏层大小、层数、查询头数量等。
- 预训练数据处理:包括源代码、文本-代码混合、合成数据、数学数据和文本数据,经过精心清洗和格式化,确保数据质量,其中代码占比 70%、文本 20% 和数学数据 10%。
- 训练策略:
- 文件级预训练:通过处理单个代码文件的内容,学习编程语言的基础知识和结构。
- 仓库级预训练:增强模型的长上下文处理能力,将上下文长度扩展到 32K tokens,并调整 Rotary Position Embedding(RoPE)的基础频率。
- 后训练与指令调优:
- 指令数据生成:通过构建特定语言智能体和自适应记忆系统等生成高质量指令数据。
- 训练策略:采用由粗到精的微调策略,先使用多样化指令样本进行微调,然后通过高质量指令样本进行监督微调。
- 特殊 Token 引入:在训练过程中引入特殊标记,帮助模型更好地理解代码。
- 长上下文能力:通过优化 RoPE 基频和应用 YaRN 机制,处理更长的上下文,有效支持代码补全和代码库理解。
- 代码生成能力:在多个代码生成基准上取得最佳表现,具备与 GPT-4o 竞争的能力。
Qwen2.5-Coder的项目地址
- 项目官网:qwenlm.github.io/blog/qwen2.5-coder
- GitHub仓库:https://github.com/QwenLM/Qwen2.5-Coder
- HuggingFace模型库:https://huggingface.co/collections/Qwen/qwen25-coder-66eaa22e6f99801bf65b0c2f
- arXiv技术论文:https://arxiv.org/pdf/2409.12186
Qwen2.5-Coder的应用场景
- 日常编程工作:开发者可利用 Qwen2.5-Coder 辅助编写代码,提高工作效率,减少重复性工作。
- 代码学习与练习:编程新手可通过 Qwen2.5-Coder 学习编程语言的语法和最佳实践,提升编程技能。
- 教育与培训:在编程教育中,Qwen2.5-Coder 可作为教学辅助工具,帮助学生理解复杂的概念,并提供即时反馈。
- 代码审查与质量保证:在代码审查过程中,Qwen2.5-Coder 可帮助识别潜在问题,提供改进建议,确保代码质量。
- 自动化测试:Qwen2.5-Coder 能够生成测试用例,助力自动化测试,提高软件测试的覆盖率与效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 粤公网安备 44011502001135号
粤公网安备 44011502001135号