













Model card for CLAP
Model card for CLAP: Contrastive Language-Audio Pretraining
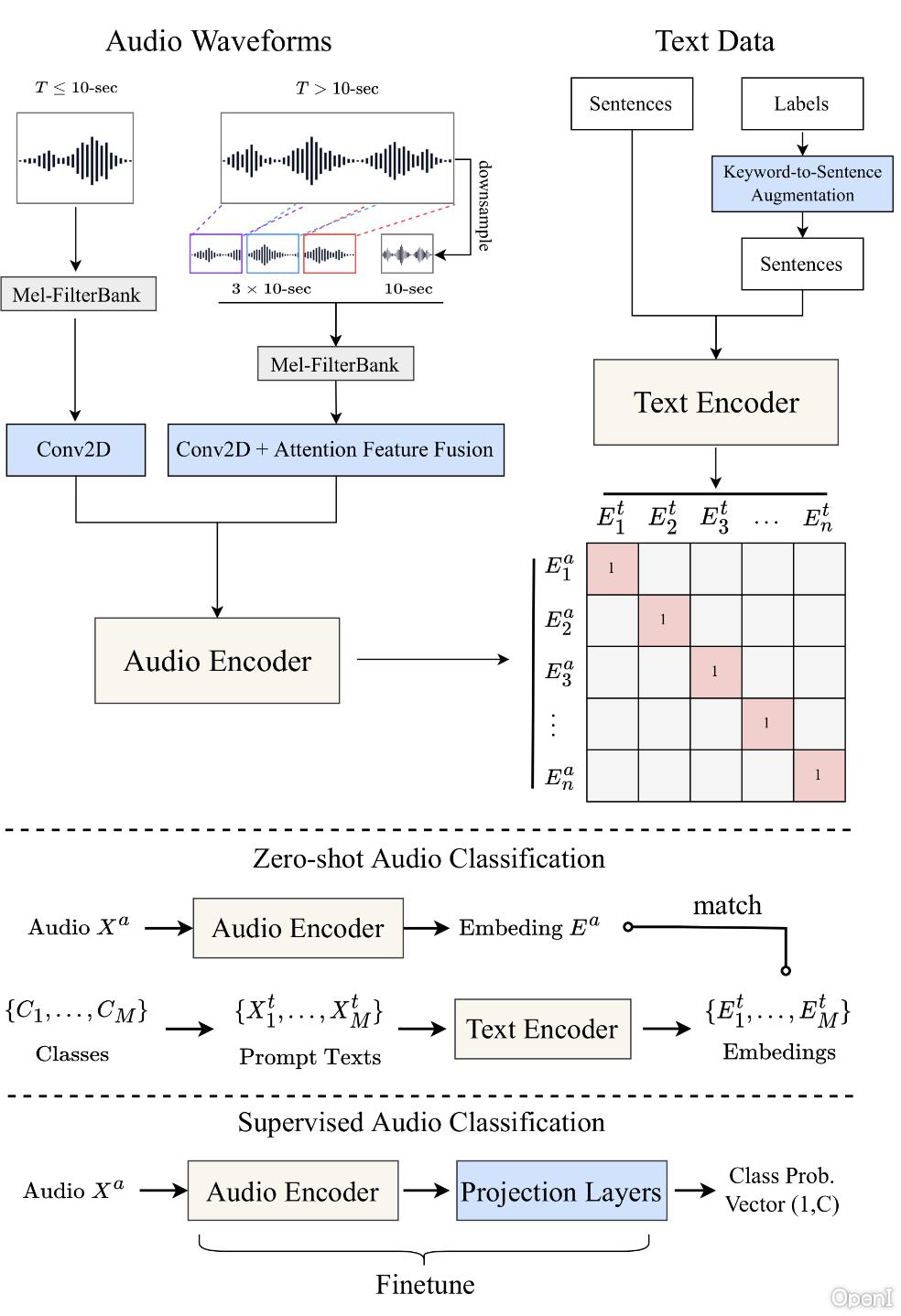
Table of Contents
- TL;DR
- Model Details
- Usage
- Uses
- Citation
TL;DR
The abstract of the paper states that:
Contrastive learning has shown remarkable success in the field of multimodal representation learning. In this paper, we propose a pipeline of contrastive language-audio pretraining to develop an audio representation by combining audio data with natural language descriptions. To accomplish this target, we first release LAION-Audio-630K, a large collection of 633,526 audio-text pairs from different data sources. Second, we construct a contrastive language-audio pretraining model by considering different audio encoders and text encoders. We incorporate the feature fusion mechanism and keyword-to-caption augmentation into the model design to further enable the model to process audio inputs of variable lengths and enhance the performance. Third, we perform comprehensive experiments to evaluate our model across three tasks: text-to-audio retrieval, zero-shot audio classification, and supervised audio classification. The results demonstrate that our model achieves superior performance in text-to-audio retrieval task. In audio classification tasks, the model achieves state-of-the-art performance in the zero-shot setting and is able to obtain performance comparable to models’ results in the non-zero-shot setting. LAION-Audio-630K and the proposed model are both available to the public.
Usage
You can use this model for zero shot audio classification or extracting audio and/or textual features.
Uses
Perform zero-shot audio classification
Using pipeline
from datasets import load_dataset
from transformers import pipeline
dataset = load_dataset("ashraq/esc50")
audio = dataset["train"]["audio"][-1]["array"]
audio_classifier = pipeline(task="zero-shot-audio-classification", model="laion/clap-htsat-fused")
output = audio_classifier(audio, candidate_labels=["Sound of a dog", "Sound of vaccum cleaner"])
print(output)
>>> [{"score": 0.999, "label": "Sound of a dog"}, {"score": 0.001, "label": "Sound of vaccum cleaner"}]
Run the model:
You can also get the audio and text embeddings using ClapModel
Run the model on CPU:
from datasets import load_dataset
from transformers import ClapModel, ClapProcessor
librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
audio_sample = librispeech_dummy[0]
model = ClapModel.from_pretrained("laion/clap-htsat-fused")
processor = ClapProcessor.from_pretrained("laion/clap-htsat-fused")
inputs = processor(audios=audio_sample["audio"]["array"], return_tensors="pt")
audio_embed = model.get_audio_features(**inputs)
Run the model on GPU:
from datasets import load_dataset
from transformers import ClapModel, ClapProcessor
librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
audio_sample = librispeech_dummy[0]
model = ClapModel.from_pretrained("laion/clap-htsat-fused").to(0)
processor = ClapProcessor.from_pretrained("laion/clap-htsat-fused")
inputs = processor(audios=audio_sample["audio"]["array"], return_tensors="pt").to(0)
audio_embed = model.get_audio_features(**inputs)
Citation
If you are using this model for your work, please consider citing the original paper:
@misc{https://doi.org/10.48550/arxiv.2211.06687,
doi = {10.48550/ARXIV.2211.06687},
url = {https://arxiv.org/abs/2211.06687},
author = {Wu, Yusong and Chen, Ke and Zhang, Tianyu and Hui, Yuchen and Berg-Kirkpatrick, Taylor and Dubnov, Shlomo},
keywords = {Sound (cs.SD), Audio and Speech Processing (eess.AS), FOS: Computer and information sciences, FOS: Computer and information sciences, FOS: Electrical engineering, electronic engineering, information engineering, FOS: Electrical engineering, electronic engineering, information engineering},
title = {Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
数据评估
本站OpenI提供的laion/clap-htsat-fused都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由OpenI实际控制,在2023年 5月 26日 下午5:54收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,OpenI不承担任何责任。
相关导航







全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。