












“鹏城·脑海”大模型官网地址:https://openi.pcl.ac.cn/extension/mind
鹏城·脑海(PengCheng Mind)通用AI大模型
2023年9月21日上午,鹏城实验室主任、中国工程院院士高文在2023华为全联接大会上正式发布了“鹏城·脑海”(PengCheng Mind)通用AI大模型,以国产化基座大模型为新一代AI大模型发展构筑新基点。
高文主任介绍,“鹏城·脑海”通用AI大模型以稠密型架构实现2000亿参数,依托“鹏城云脑II”国产化AI算力平台进行全程预训练,采用了MindSpore昇思国产化深度学习框架,完善了大规模并行训练策略、底层算子性能和容错机制,显著提升了国产算力平台的训练效率,并构建了一套涵盖中文、英文及50余个“一带一路”沿线国家及地区语种的多样化语料数据集和数据质量评估工具集。本次发布的是以中文为核心的“鹏城·脑海”基础版,将在OpenI启智社区向全社会开源。


脑海大模型版本
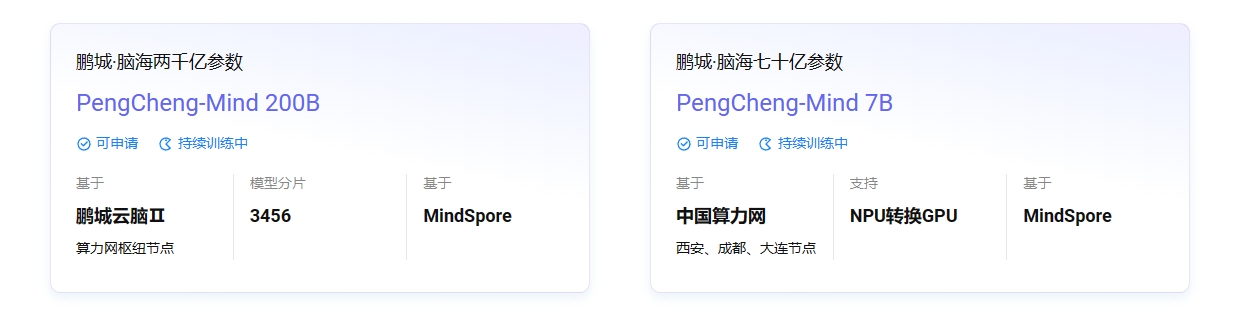
此次发布的脑海大模型包括“两千亿参数”和“七十亿参数”的PengCheng-Mind 200B、PengCheng-Mind 7B,均是基于“中国算力网”国产化AI算力平台和“MindSpore”国产化深度学习框架的全国产大模型。其中PengCheng-Mind 7B的模型,支持NPU版本到GPU版本的转换。
脑海大模型历史消息
2023年5月29日,在第二届粤港澳区(广东)算力产业大会暨首届中国算力网大会上,中国工程院院士、鹏城实验室主任高文透露:鹏城实验室将推出“鹏城·脑海”大模型计划,打造国内首个完全自主可控、安全可控、开源开放的自然语言预训练大模型底座。面向数字政务、智慧金融、智能制造等应用场景,鹏城实验室将开放基于“鹏城·脑海”大模型底座的合作,共建国产自主可控预训练大模型健康生态。

依托“鹏城云脑”,诞生了全球首个全开源的两千亿参数中文预训练语言大模型“鹏城·盘古”、全球首个知识增强千亿大模型“鹏城-百度·文心”、性能达国际先进水平的十亿参数视觉大模型“鹏城·大圣”等大模型。


“鹏城·脑海”大模型推广计划

“鹏城·脑海”大模型将进一步依托“中国算力网”接入的协同算力,以“算力网算力调度+模型赋能”相结合的方式,携手国家新一代AI公共算力平台,共同推动国产化AI大模型的持续演进与部署应用,最终打造一个基于“中国算力网”的各类领域AI大模型及应用生态的数字化基座。与此同时,实验室将牵头成立“鹏城·脑海”开源联合体,广泛联合企业、高校和科研院所,通过这一全新的开源群智合作模式,“一揽子”提供覆盖压缩、部署、微调与价值对齐等环节的模型工具,并加强大模型的开源管理与资源共享,加速为千行百业插上人工智能的“翅膀”。

数据评估
本站OpenI提供的脑海大模型都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由OpenI实际控制,在2023年 9月 15日 上午9:21收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,OpenI不承担任何责任。
相关导航





全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。