













鹏程·盘古α是业界首个2000亿参数以中文为核心的预训练生成语言模型,目前开源了两个版本:鹏程·盘古α和鹏程·盘古α增强版,并支持NPU和GPU两个版本,支持丰富的场景应用。
项目简介
鹏程·盘古α是业界首个2000亿参数以中文为核心的预训练生成语言模型,目前开源了两个版本:鹏程·盘古α和鹏程·盘古α增强版,并支持NPU和GPU两个版本,支持丰富的场景应用,在知识问答、知识检索、知识推理、阅读理解等文本生成领域表现突出,具备较强的少样本学习的能力。
基于盘古系列大模型提供大模型应用落地技术帮助用户高效的落地超大预训练模型到实际场景。整个框架特点如下:
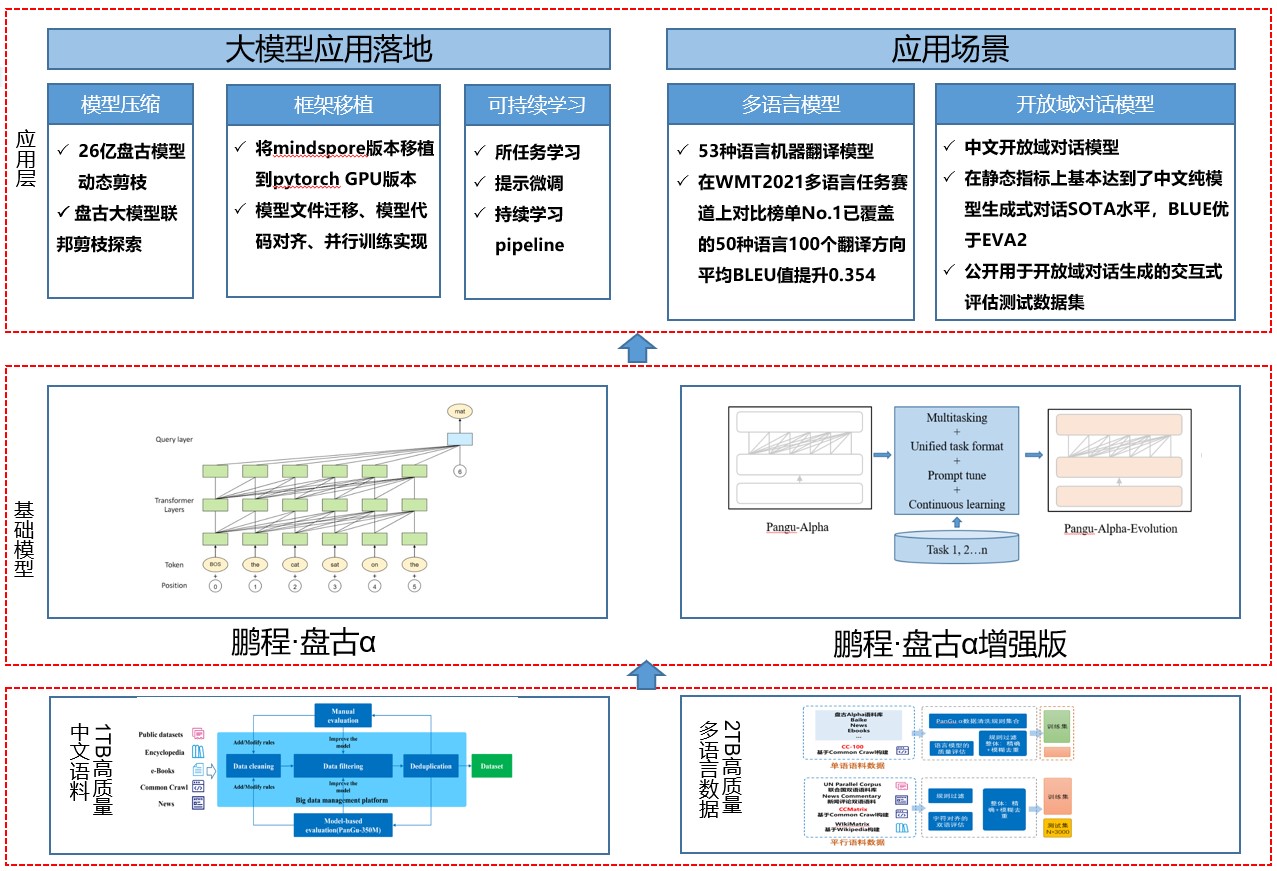
主要有如下几个核心模块:
- 数据集:从开源开放数据集、common crawl数据集、电子书等收集近80TB原始语料,构建了约1.1TB的高质量中文语料数据集、53种语种高质量单、双语数据集2TB。
- 基础模块:提供预训练模型库,支持常用的中文预训练模型,包括鹏程·盘古α、鹏程·盘古α增强版等。
- 应用层:支持常见的NLP应用比如多语言翻译、开放域对话等,支持预训练模型落地工具,包括模型压缩、框架移植、可持续学习,助力大模型快速落地。
交流社区
数据评估
关于鹏程·盘古α大模型特别声明
本站OpenI提供的鹏程·盘古α大模型都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由OpenI实际控制,在2023年 6月 14日 上午11:53收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,OpenI不承担任何责任。
相关导航







暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。