













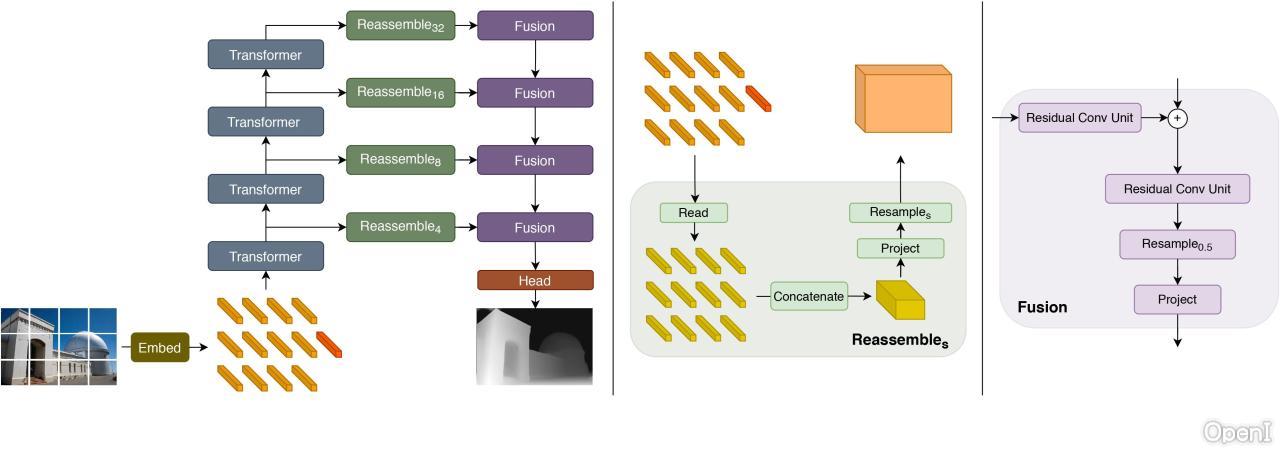
密集预测变压器(DPT)模型是在140万张图像上进行单目深度估计训练的。它是由Ranftl等人在2021年的论文“用于密集预测的视觉变压器”中介绍的,并首次在此存储库中发布。DPT使用视觉变压器(ViT)作为骨干,并在其上方添加了一个颈部+头部,用于单目深度估计。
模型是由Hugging Face团队和英特尔联合编写的。
以下是如何在图像上使用此模型进行零样本深度估计的方法:
from transformers import DPTImageProcessor, DPTForDepthEstimation
import torch
import numpy as np
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = DPTImageProcessor.from_pretrained("Intel/dpt-large")
model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large")
# prepare image for the model
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
predicted_depth = outputs.predicted_depth
# interpolate to original size
prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image.size[::-1],
mode="bicubic",
align_corners=False,
)
# visualize the prediction
output = prediction.squeeze().cpu().numpy()
formatted = (output * 255 / np.max(output)).astype("uint8")
depth = Image.fromarray(formatted)
数据评估
本站OpenI提供的Intel/dpt-large-Hugging Face都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由OpenI实际控制,在2023年 5月 26日 下午6:07收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,OpenI不承担任何责任。
相关导航







全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。