AIGC动态欢迎阅读
原标题:ViT-22B被取代了!商汤开源60亿视觉参数大模型InternVL刷爆多模态榜单!
关键字:视觉,报告,模型,语言,图像
文章来源:算法邦
内容字数:7130字
内容摘要:
论文链接:
https://arxiv.org/abs/2312.14238开源代码:
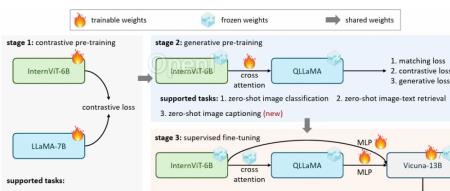
https://github.com/OpenGVLab/InternVL01引言大型语言模型(LLMs)在开放世界语言任务中展现出令人印象深刻的能力,极大地推动了人工通用智能(AGI)系统的发展。它们的模型规模和性能仍在快速增长。利用LLMs的视觉大型语言模型(VLLMs)也取得了重大突破,实现了复杂的视觉-语言对话和互动。然而,与LLMs的快速增长相比,视觉和视觉-语言基础模型的进展滞后。
为了将视觉模型与语言模型(LLMs)进行联系,现有的视觉语言联合模型(VLLMs)常常采用轻量级的“粘合”层,例如QFormer或线性投影,来对齐视觉和语言模型的特征。然而,这种对齐存在以下几个局限性:(1)参数规模的不一致。LLMs的参数规模已经达到1000亿,而广泛使用的VLLMs的视觉编码器仍在10亿左右。这种差距可能导致LLMs的能力被低估。(2)表示的不一致。在纯视觉数据上训练的视觉模型或与BERT系列对齐的模型往往与LLMs存在表示上的不一致。(3)连接效率低下。粘合层通常是轻量级的和随机初始化的
原文链接:ViT-22B被取代了!商汤开源60亿视觉参数大模型InternVL刷爆多模态榜单!
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:「算法邦」,隶属于智猩猩,关注大模型、生成式AI、计算机视觉三大领域的研究与开发,提供技术文章、讲座、在线研讨会。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。