AIGC动态欢迎阅读
原标题:靠Scaling Laws炼出4D版视频生成模型,多伦多大学北交大等携手开源81K高质量数据集
关键字:模型,物体,内容,视频,数据
文章来源:量子位
内容字数:0字
内容摘要:
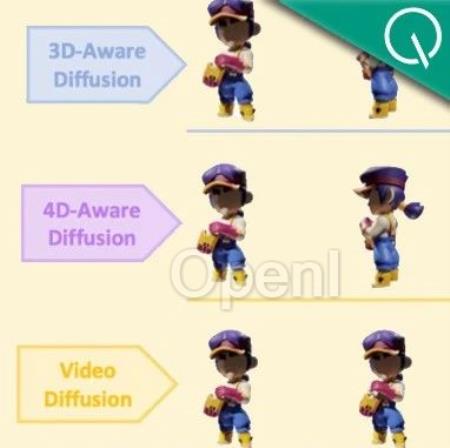
Diffusion4D团队 投稿量子位 | 公众号 QbitAI只需几分钟、一张图或一句话,就能完成时空一致的4D内容生成。
注意看,这些生成的3D物体,是带有动作变化的那种。也就是在3D物体的基础之上,增加了时间维度的变化。
这一成果,名为Diffusion4D,来自多伦多大学、北京交通大学、德克萨斯大学奥斯汀分校和剑桥大学团队。
具体而言,Diffusion4D整理筛选了约81K个4D assets,利用8卡GPU共16线程,花费超30天渲染得到了约400万张图片,包括静态3D物体环拍、动态3D物体环拍,以及动态3D物体前景视频。
作者表示,该方法是首个利用大规模数据集,训练视频生成模型生成4D内容的框架,目前项目已经开源所有渲染的4D数据集以及渲染脚本。
研究背景过去的方法采用了2D、3D预训练模型在4D(动态3D)内容生成上取得了一定的突破,但这些方法主要依赖于分数蒸馏采样(SDS)或者生成的伪标签进行优化,同时利用多个预训练模型获得监督不可避免的导致时空上的不一致性以及优化速度慢的问题。
4D内容生成的一致性包含了时间上和空间上的一致性,它们分别在视频生成模型和多视图生成
原文链接:靠Scaling Laws炼出4D版视频生成模型,多伦多大学北交大等携手开源81K高质量数据集
联系作者
文章来源:量子位
作者微信:QbitAI
作者简介:追踪人工智能新趋势,关注科技行业新突破
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。