AIGC动态欢迎阅读
原标题:英伟达又赚到了!FlashAttention3来了:H100利用率飙升至75%
关键字:注意力,矩阵,精度,速度,算法
文章来源:机器之心
内容字数:0字
内容摘要:
机器之心报道
编辑:陈陈、小舟740 TFLOPS!迄今最强 FlashAttention 来了。随着大型语言模型(LLM)加速落地,扩展模型上下文窗口变得越来越重要。然而,Transformer 架构的核心 —— 注意力层的时间复杂度和空间复杂度与输入序列长度的平方成正比。这使得扩展模型上下文窗口存在挑战。
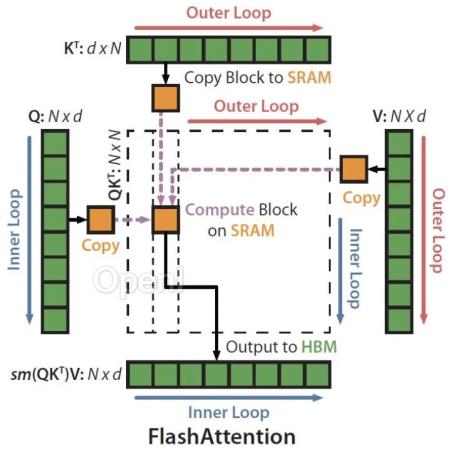
2022 年,一种快速、内存高效的注意力算法 ——FlashAttention 问世,该算法无需任何近似即可加速注意力并减少内存占用。
FlashAttention 对注意力计算进行重新排序的算法,并利用 tiling 和重计算来显著加快计算速度,将内存使用量从序列长度的二次减少到线性。2023 年,研究团队宣布推出 FlashAttention-2,在算法、并行化和工作分区等方面有了显著改进。
现在,来自 Meta、英伟达、Together AI 等机构的研究者宣布推出 FlashAttention-3,它采用了加速 Hopper GPU 注意力的三种主要技术:
通过 warp-specialization 重叠整体计算和数据移动;
交错分块 matmul 和 softmax
原文链接:英伟达又赚到了!FlashAttention3来了:H100利用率飙升至75%
联系作者
文章来源:机器之心
作者微信:almosthuman2014
作者简介:专业的人工智能媒体和产业服务平台
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。