AIGC动态欢迎阅读
原标题:大模型压缩KV缓存新突破,中科大提出自适应预算分配,工业界已落地vLLM框架
关键字:报告,注意力,预算,分配,团队
文章来源:量子位
内容字数:0字
内容摘要:
中科大博士冯源 投稿量子位 | 公众号 QbitAI改进KV缓存压缩,大模型推理显存瓶颈迎来新突破——
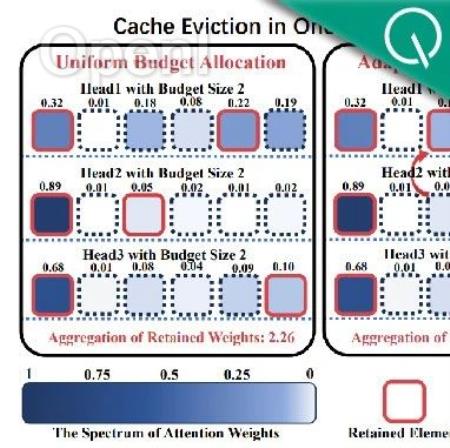
中科大研究团队提出Ada-KV,通过自适应预算分配算法来优化KV缓存的驱逐过程,以提高推理效率。
打破KV Cache压缩将所有注意力头分配相同压缩预算的常规做法,针对不同的注意力头进行适配性压缩预算分配
展开来说,由于大模型在自回归生成过程中,每生成一个新token都需要将对应的KV矩阵存储下来,这导致缓存随着生成序列长度的增加而急剧膨胀,引发内存和I/O延迟问题,尤其在长序列推理中尤为突出。
因此,KV缓存压缩成为了一项必要的优化。
不过令人头秃的是,现有压缩方法往往在各个注意力头之间平均分配预算,未能考虑其特性差异。
而中科大团队在注意到——不同注意力头关注度存在差异后,对其进行适配性压缩预算分配,通过精细化运作带来更高的压缩质量。
相关研究不仅在学术界引起讨论,更实现了工业界开源落地。
例如,Cloudflare workers AI团队进一步将其改进落地于工业部署常用的vLLM框架中,并发布技术报告,开源全部代码。
KV缓存压缩从均匀性预算分配→适配性预算分配一开始,Ada
原文链接:大模型压缩KV缓存新突破,中科大提出自适应预算分配,工业界已落地vLLM框架
联系作者
文章来源:量子位
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。