MOFA-Video是一个由腾讯AI实验室与东京大学研究人员共同开发并开源的可控图像生成视频模型。该技术利用生成场适应器对静态图像进行动态处理,生成高质量的视频内容。MOFA-Video基于预训练的Stable Video Diffusion模型,借助手动轨迹、面部标记序列或音频等稀疏控制信号,能够精细调控视频生成中的动作。这一模型的创新之处在于,它不仅可以单独使用这些控制信号,还能以零样本的方式进行复杂动画制作,为用户提供了一种全新的高可控性图像动画解决方案。
MOFA-Video是什么
MOFA-Video是腾讯AI实验室和东京大学的研究者共同推出的开源模型,旨在实现可控的图像生成视频。其核心技术是生成场适应器,能够将静态图像转化为动态视频。MOFA-Video在Stable Video Diffusion模型的基础上,通过稀疏控制信号如手动轨迹、面部标记或音频,实现对视频中动作的精细调控。无论是简单的动画还是复杂的场景,MOFA-Video都能通过组合不同的控制信号,以零样本的方式完成高质量的动画生成。
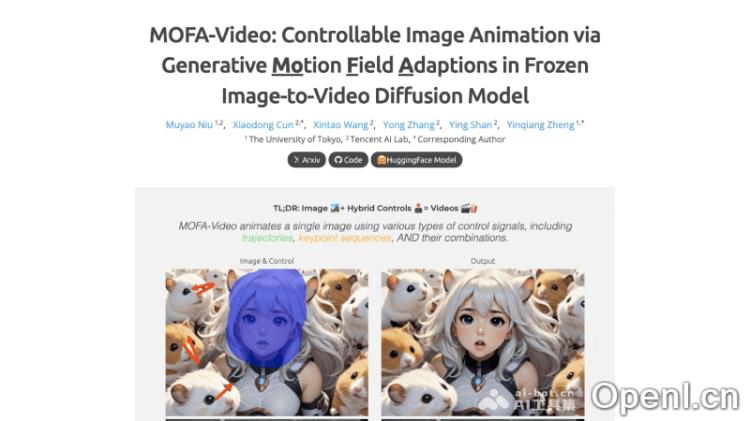
主要功能
- 轨迹控制动画:用户可以在图像上手动绘制轨迹,从而指导MOFA-Video生成相应的视频动画,适合需要精细控制物体或镜头移动的场景。
- 面部关键点动画:系统利用面部识别技术获取的关键点数据,实现逼真的面部表情和头部动作动画。
- 混合控制动画:MOFA-Video支持将轨迹控制与面部关键点控制结合,生成同步的面部表情与身体动作,创造复杂的多部分动画效果。
- 音频驱动面部动画:通过分析音频信号,生成与语音或音乐同步的面部动画,如口型同步等。
- 视频驱动面部动画:利用参考视频,MOFA-Video能够让静态图像中的面部动作模仿视频中的表情,实现动态表现。
- 零样本多模态控制:支持不同控制信号无须额外训练即可组合使用,提升动画生成的灵活性与多样性。
- 长视频生成能力:通过周期性采样策略,MOFA-Video可以生成比传统模型更长的视频,突破帧数的限制。
- 用户友好的界面操作:MOFA-Video提供基于Gradio的直观界面,用户无需专业编程技能即可轻松进行动画生成。

产品官网
- 官方项目主页:https://myniuuu.github.io/MOFA_Video
- GitHub代码库:https://github.com/MyNiuuu/MOFA-Video
- 基于轨迹的图像动画Gradio演示和模型检查点:https://huggingface.co/MyNiuuu/MOFA-Video-Traj
- Gradio演示和混合控制图像动画检查点:https://huggingface.co/MyNiuuu/MOFA-Video-Hybrid
应用场景
MOFA-Video适用于多种场景,包括但不限于影视制作、游戏开发、广告创意和社交媒体内容创作。无论是需要精确控制的动画场景,还是想要生成与音频同步的动态视频,MOFA-Video都可以为创作者提供强大的支持。
常见问题
1. MOFA-Video是否需要编程知识?
不需要。MOFA-Video提供了友好的用户界面,任何人都可以轻松上手。
2. MOFA-Video支持哪些类型的控制信号?
MOFA-Video支持轨迹控制、面部关键点、音频驱动和视频驱动等多种控制信号。
3. 如何获取MOFA-Video的最新版本?
用户可以访问其官方网站和GitHub代码库获取最新版本和更新信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。