多语言多模态的文本图像Embedding模型
原标题:Jina CLIP v2:为多模态RAG设计的向量模型
文章来源:智猩猩GenAI
内容字数:2851字
2024中国生成式AI大会(上海站)预告
根据大会预告,智猩猩共同主办的2024中国生成式AI大会将于12月5-6日在上海举办。此次大会邀请了40多位嘉宾参会演讲,包括北大(临港)大模型对齐中心的徐骅,腾讯优图实验室的吴贤,以及其他知名企业的代表。欢迎感兴趣的朋友扫名参加。
多模态AI的基础:统一向量表示
多模态数据通过统一的向量表示,实现了不同模态数据的互相检索和理解转换,这是多模态AI应用的基石。Jina.ai最近推出了全新的多语言多模态向量模型Jina CLIP v2,显著增强了跨模态检索的能力,并为多模态RAG应用奠定了基础。
Jina-CLIP V2的主要特点
1. **性能提升**:与前版本相比,Jina-CLIP V2在文本-图像和文本-文本检索任务中提高了3%的性能,且文本编码器的检索能力与前沿模型相当。
2. **多语言支持**:该模型支持89种语言的多语言-图像检索,相较于同类模型表现出高达4%的性能提升。
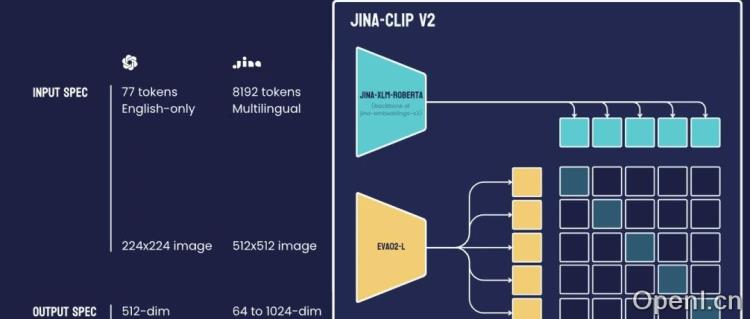
3. **更高图像分辨率**:Jina-CLIP V2支持512×512的输入图像分辨率,显著提升了对细节的处理能力。
4. **可变维度输出**:引入了套娃式表示学习技术,用户可根据需求获取不同维度的向量输出,同时降低存储成本。
模型结构与性能表现
Jina-CLIP V2的参数量达到0.9B,融合了文本编码器Jina-XLM-RoBERTa和视觉编码器EVA02-L14。这种结合使得模型在多模态任务中表现优异,能够高效处理文本和图像数据。
在跨模态检索任务中,Jina-CLIP V2支持89种语言,并在多个主要语种中均表现优异,性能与最先进的CLIP模型相当。模型引入的套娃式表征学习技术,实现了灵活的输出维度,展现出极高的压缩效率,即使在进行大幅度维度削减后,模型仍能保持良好的性能。
总结
Jina-CLIP V2作为一款先进的多模态embedding模型,凭借其卓越的性能和多语言支持,为未来多模态AI应用的发展提供了坚实的基础。欢迎关注相关内容,获取更多信息。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下矩阵账号之一,聚焦大模型开启的通用人工智能浪潮。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。