详细解读ppo理论知识
原标题:人人都能看懂的RL-PPO理论知识
文章来源:智猩猩GenAI
内容字数:21030字
文章要点总结
本文围绕强化学习的核心概念和算法进行了系统的阐述,特别是聚焦于策略梯度、Actor-Critic方法及PPO(Proximal Policy Optimization)算法的细节。以下是文章的主要内容要点:
策略(Policy)
策略可分为确定性策略和随机性策略。本文主要讨论随机性策略,智能体在状态下根据策略选择动作。
奖励(Reward)
奖励是由当前状态、执行的动作和下一状态共同决定的。本文介绍了单步奖励、T步累积奖励以及折扣奖励的概念。
轨迹和状态转移
轨迹是智能体与环境交互后得到的状态、动作和奖励的序列,称为episodes或rollouts。
Policy-based强化学习优化目标
强化学习的目标是找到一个策略,使得其产生的轨迹的回报期望尽量高。在此背景下,讨论了基于策略的优化目标及其梯度推导。
价值函数(Value Function)
介绍了状态价值函数、动作价值函数及其相互关系,强调了优势函数和TD error的定义及其重要性。
Actor-Critic方法
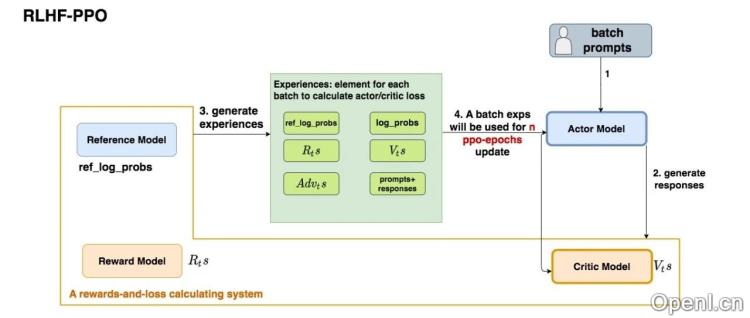
Actor-Critic方法通过使用两个神经网络来分别表示策略(Actor)和价值(Critic),并介绍了它们之间的关系和优化目标。
PPO算法
PPO在朴素Actor-Critic基础上做出了改进,采用重要性采样和GAE(Generalized Advantage Estimation)来平衡优势函数的方差与偏差,提升算法性能。
通过对强化学习理论的深入分析,本文旨在帮助读者更好地理解RL的工作原理,特别是Actor-Critic框架及其在实践中的应用。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。