EMOVA(EMotionally Omni-present Voice Assistant)是一种先进的多模态全能模型,由香港科技大学、香港大学及华为诺亚方舟实验室等机构联合研发。该产品能够处理图像、文本和语音三种模态,支持全模态的交互,使用户能够体验到更自然、更人性化的人机互动。
EMOVA是什么
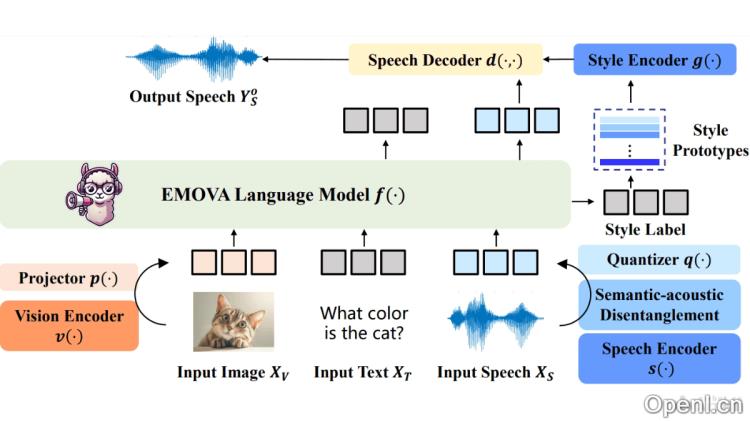
EMOVA是一款多模态全能模型,旨在通过处理图像、文本和语音数据,实现全方位的交互体验。借助语义声学分离技术及轻量级情感控制模块,EMOVA能够生成富有情感的语音对话,大幅提升人机交互的自然度和亲和力。该模型在视觉语言和语音任务中均展现出卓越的性能,为人工智能领域提供了新的思路,并推动了情感交互技术的发展。
EMOVA的主要功能
- 多模态处理能力:能够同时处理图像、文本和语音,实现全面的交互体验。
- 情感丰富的对话:基于先进的语义声学分离技术和情感控制模块,能够生成表达如快乐、悲伤等情感的语音。
- 端到端的语音对话:支持从语音输入到语音输出的完整对话流程,无需任何外部语音处理工具。
- 视觉语言理解:能够理解和生成与图像内容相关的文本,展现卓越的视觉语言理解能力。
- 语音理解与生成:具备语音识别和合成的能力,能理解并生成自然流畅的语音。
- 个性化语音生成:支持对语音的风格、情感、语速和音调进行调整,满足多样化的交流需求。
EMOVA的技术原理
- 连续视觉编码器:利用持续的视觉编码器提取图像的细致特征,并将其编码为与文本嵌入空间相匹配的向量表示。
- 语义-声学分离的语音分词器:将输入语音分解为语义内容和声学风格,确保语义内容与语言模型对接,同时控制情感和音调等声学特征。
- 轻量级风格模块:引入轻量级模块来调节语音输出的情感和音调,使对话更加自然和富有表现力。
- 全模态对齐:基于文本作为桥梁,利用公开的图像-文本和语音-文本数据进行全模态训练,确保不同模态之间的有效对接。
- 端到端架构:采用直接的端到端架构,从多模态输入生成文本和语音输出,实现输入与输出的直接映射。
- 数据高效的全模态对齐方法:通过双模态数据来提升全模态能力,减少对稀缺三模态数据的依赖,并通过联合优化增强跨模态能力。
EMOVA的项目地址
- 项目官网:emova-ollm.github.io
- arXiv技术论文:https://arxiv.org/pdf/2409.18042
EMOVA的应用场景
- 客户服务:在客户服务领域,EMOVA可作为智能机器人,通过语音、文本和图像与客户进行互动,提供情感化的支持。
- 教育辅助:作为虚拟教师,EMOVA能够通过多模态交互,为用户提供个性化的教学和学习体验。
- 智能家居控制:在智能家居系统中,EMOVA可以作为控制单元,通过语音命令控制家中设备,并提供视觉反馈。
- 健康咨询:在医疗健康领域,EMOVA能够提供语音交互的健康咨询服务,分析用户的问题并提供相应建议。
- 紧急救援:在危急情况下,EMOVA通过语音识别和图像分析,快速评估现场情况并提供救援指导。
常见问题
- EMOVA支持哪些语言?:EMOVA支持多种语言的处理,具体可根据项目更新查看。
- 如何使用EMOVA进行开发?:开发者可以参考项目官网提供的文档和示例进行集成和开发。
- EMOVA的使用场景有哪些?:EMOVA广泛应用于客户服务、教育、智能家居、健康咨询等多个领域。
- EMOVA的情感识别能力如何?:EMOVA通过情感控制模块能够生成多种情感色彩的语音,提升交互的自然性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。