Large Motion Model – 商汤科技联合南洋理工推出的统一多模态生成模型
Large Motion Model简介
Large Motion Model(LMM)是一种创新的多模态生成模型,由新加坡南洋理工大学S-Lab与商汤科技的研究团队联合开发。LMM能够处理多种生成任务,如将文本转化为、将音乐转换为舞蹈等,并在多个基准测试中展现出与专业模型相媲美的卓越性能。该模型通过整合不同模态、格式和任务的数据,构建了一个全面的MotionVerse数据集,并采用了先进的ArtAttention机制和预训练策略,实现对身体各部位的精准控制和丰富的知识泛化能力。LMM在面对未见任务时展现出出色的泛化能力,为未来多模态生成的研究开辟了新视角。
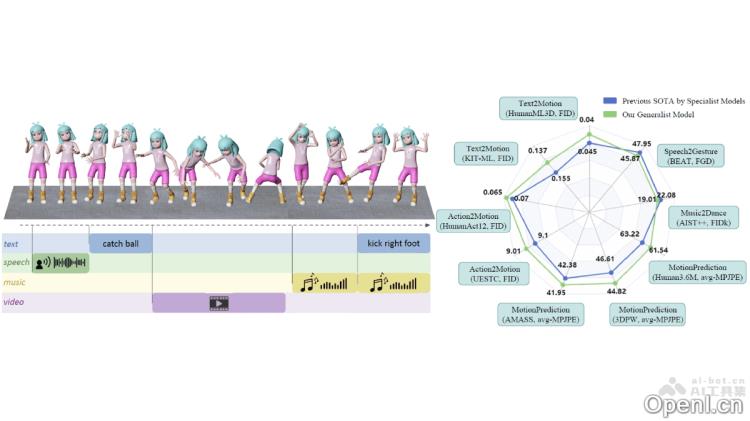
Large Motion Model的核心功能
- 多任务生成:支持多种生成任务,包括文本到、音乐到舞蹈、动作到等。
- 数据集的整合:构建了MotionVerse数据集,基于多种模态、格式和任务的数据实现统一的表示。
- 精准控制:通过ArtAttention机制,支持对不同身体部位进行精确的控制,提升生成的细致度。
- 强大的泛化能力:在多种未见任务中有效地生成,展现出出色的泛化能力。
- 多模态输入处理:能够同时处理文本、音乐、视频等多种输入模态,并生成相应的输出。
Large Motion Model的技术原理
- 统一的数据集(MotionVerse):基于MotionVerse数据集,该数据集涵盖了多种任务和模态的数据,采用TOMATO表示法整合不同格式的数据。
- Diffusion Transformer骨干网络:基于Transformer框架的扩散模型,使用去噪扩散概率模型(DDPM)生成高质量的序列。
- ArtAttention机制:创新的注意力机制ArtAttention,结合身体部位感知建模,使模型能够控制和学习不同身体部位。
- 预训练策略:采用随机帧率和多种掩码技术的预训练策略,增强模型对不同数据源的学习和泛化能力。
- 零样本学习:通过零样本方法生成长序列,使模型在没有额外样本的情况下进行生成。
项目资源
- 项目官网:https://mingyuan-zhang.github.io/projects/LMM
- GitHub仓库:https://github.com/mingyuan-zhang/LMM
- arXiv技术论文:https://arxiv.org/pdf/2404.01284
- 在线体验Demo:https://huggingface.co/spaces/mingyuan/LMM
Large Motion Model的应用领域
- 动画与游戏制作:生成生动的角色动画,显著减少手动制作动画所需的时间和成本,提升动画制作的效率。
- 虚拟现实(VR)与增强现实(AR):在VR和AR应用中,生成与用户动作相匹配的虚拟角色动作,增强用户的沉浸体验。
- 影视制作:生成电影中的特殊效果,如复杂的打斗场景或舞蹈动作,提高制作效率。
- 分析与训练:分析员的动作并提供训练建议,生成标准动作模板。
- 机器人技术:训练机器人执行复杂的人类动作,提升其在服务、医疗或工业领域的应用能力。
常见问题
- LMM的训练数据来源是什么?:LMM基于MotionVerse数据集,该数据集整合了多种模态和任务的数据。
- 如何使用LMM生成?:用户可以通过输入文本、音乐或视频等多种模态,使用LMM生成相应的输出。
- LMM支持哪些类型的生成任务?:LMM支持从文本到、音乐到舞蹈等多种生成任务。
- LMM的输出质量如何?:在多个基准测试中,LMM展现了与专家模型相媲美的输出质量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。