为清晰理解众多VLM对视觉输入的处理方式,整理了几篇代表性的工作。
原标题:VLM多模态大模型的视觉编码策略
文章来源:智猩猩GenAI
内容字数:2135字
AI多模态视觉语言模型(VLM)在自动驾驶领域的应用
本文首先介绍了即将在北京举办的第四届全球自动驾驶峰会,峰会将涵盖自动驾驶的多个前沿领域,包括视觉语言模型等技术研讨会。随后,文章重点关注了视觉语言模型(VLM)在图像处理方面的最新进展,并对几篇代表性论文进行了总结和分析。
1. 视觉语言模型(VLM)概述
视觉语言模型 (VLM) 旨在融合视觉和语言信息,实现更高级别的多模态理解和生成能力。其核心在于高效的视觉编码器,负责提取图像中不同尺寸的视觉特征。本文着重分析了不同VLM在视觉编码器设计上的差异。
2. 不同VLM视觉编码器的比较
文章对六种代表性VLM的视觉编码器进行了比较,总结如下:
- InternVL: 使用大型视觉基础模型InternViT-6B (基于原始ViT架构),并通过一个8B的LLM进行微调。
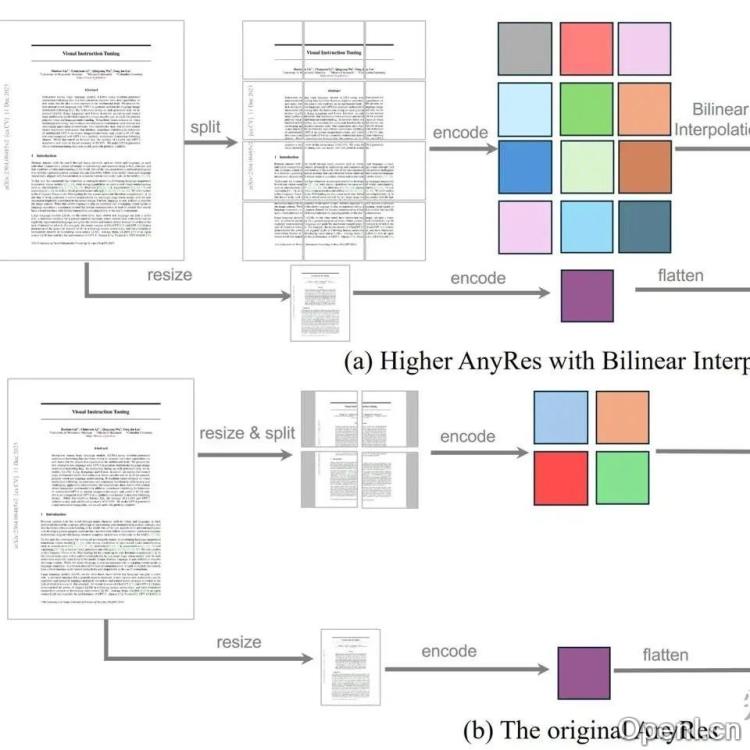
- LLaVA-OneVision: 采用AnyRes技术,支持任意尺寸高分辨率图像处理。对单图进行网格裁剪处理,多图或视频则逐图处理。实验表明,提高分辨率比增加token数量更有效。
- Long Context Transfer from Language to Vision: 提出UniRes技术,相比AnyRes,去除了全图缩略图,对每个网格进行2×2池化。
- Pixtral: 随机初始化训练Pixtral-Vit,支持各种分辨率,并加入行结束标记token和门控机制。利用相对旋转位置编码(RoPE-2D)处理不同尺寸图像。
- Qwen2-VL: 类似Pixtral,采用2D-RoPE,并提出M-RoPE统一编码图像、视频和文本位置信息。
- Idefics2: 使用NaVit视觉编码器,支持动态分辨率,无需图像分割,通过将不同图像序列打包成一个长序列,并限制自注意力机制在当前图像序列内应用来处理不同尺寸的图像。
3. 视觉编码器技术的演进趋势
从上述VLM的视觉编码器设计可以看出,研究者们不断探索更高效、更灵活的方案,以应对不同分辨率、不同类型(单图、多图、视频)的视觉输入。 AnyRes和UniRes等技术旨在高效处理高分辨率图像,而RoPE-2D和M-RoPE等位置编码技术则提升了模型对不同尺寸图像的适应性。动态分辨率处理能力也成为一个重要的发展方向。
4. VLM在自动驾驶中的应用前景
VLM技术在自动驾驶领域具有巨大的应用潜力。通过对道路场景图像和文本信息的理解,VLM可以辅助自动驾驶系统进行更准确的环境感知、决策规划和人机交互。例如,VLM可以用于理解交通标志、路牌等信息,以及对复杂路况进行语义理解,从而提升自动驾驶系统的安全性与可靠性。
总而言之,VLM技术的快速发展为自动驾驶系统带来了新的机遇,其在视觉感知、决策规划等方面的应用值得期待。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。