Deepseek真是越来越强了。
原标题:Deepseek R1 Zero成功复现全过程记录
文章来源:智猩猩GenAI
内容字数:6393字
基于规则的强化学习提升大型语言模型逻辑推理能力
本文介绍了一个利用强化学习 (RL) 提升大型语言模型 (LLM) 逻辑推理能力的项目。该项目使用 Qwen 7B 作为基座模型,通过三阶段的基于规则的强化学习,显著提高了模型在逻辑推理任务上的准确率,并涌现出一些令人惊喜的能力。
1. 项目成果
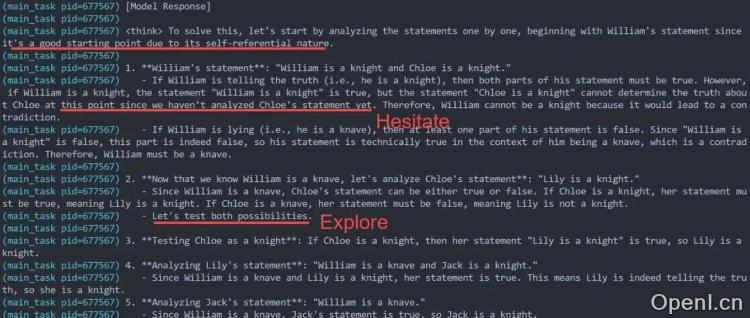
该项目成功地将 Qwen 7B 模型在逻辑推理任务上的准确率从 0.2 提升至 0.41,超越了 GPT-4 (准确率约 0.3)。更重要的是,模型在 RL 训练后涌现出了一些高级推理能力,例如:迟疑、多路径探索、回溯、阶段性总结以及答案验证等。此外,模型的平均回复长度也增加了约 50%。
2. 实验设置
该项目使用了不到 2000 条人工合成的训练数据,这些数据类似于“老实人和骗子”类型的益智题。为了避免奖励黑客行为,奖励函数仅由格式奖励和答案奖励两部分组成。基座模型选择 Qwen 7B,放弃了最初选择的 Qwen-math-7B,因为后者指令跟随能力较弱,且输出风格难以控制。RL 算法采用 Reinforce,训练批次大小为 8。
3. 三阶段强化学习
该项目采用三阶段 RL 训练策略:
- 阶段一:课程学习与格式遵循:使用简单逻辑题进行预训练,重点学习 “ 和 “ 标签的格式。此阶段模型快速学习了格式,准确率也得到提升。
- 阶段二:高温采样与大量 rollout:使用更复杂的逻辑题进行训练,并采用高温采样 (温度约 1.2) 和大 rollout 来增加模型输出的多样性,探索更丰富的推理策略。此阶段模型出现了一些有趣的“崩坏”现象,例如试图在输出答案后重新进入思考阶段,但被格式奖励惩罚。
- 阶段三:漫长的退火采样:逐步降低采样温度,模型输出逐渐成熟,具备了迟疑、回溯、总结和验证等高级推理能力。此阶段模型收敛速度较慢。
4. 令人惊喜的发现
该项目中,模型出现了一些意想不到的现象:模型有时会混合使用中文和英文进行思考,最终答案仍为英文;模型的回复长度显著增加,平均长度提升了约 50%。这些现象暗示了模型在推理过程中可能使用了人类难以理解的策略。
5. 未来工作
研究者计划进一步探索模型输出中语言混合现象的原因,以及模型内部的推理机制。此外,他们还计划将该模型应用于其他逻辑推理任务,例如 GSM8K。
6. 总结
该项目通过三阶段基于规则的强化学习,成功地提升了 Qwen 7B 模型的逻辑推理能力,并涌现出了一些高级推理能力。该项目的研究结果为 LLM 的逻辑推理能力提升提供了新的思路和方法。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。