尝试做了一波 r1-zero 的简单的复现实验
原标题:DeepSeek-R1-ZERO 尝试复现的一些现象分享
文章来源:智猩猩GenAI
内容字数:6329字
DeepSeek R1-Zero 复现实验及结果分析
本文总结了作者基于OpenRLHF框架,使用Qwen-2.5 1.5B BASE模型复现DeepSeek R1-Zero实验的结果及一些有趣的现象。实验主要探究了不同奖励函数和数据集对模型性能的影响,并对模型学习过程中的若干现象进行了分析。
1. 实验设置
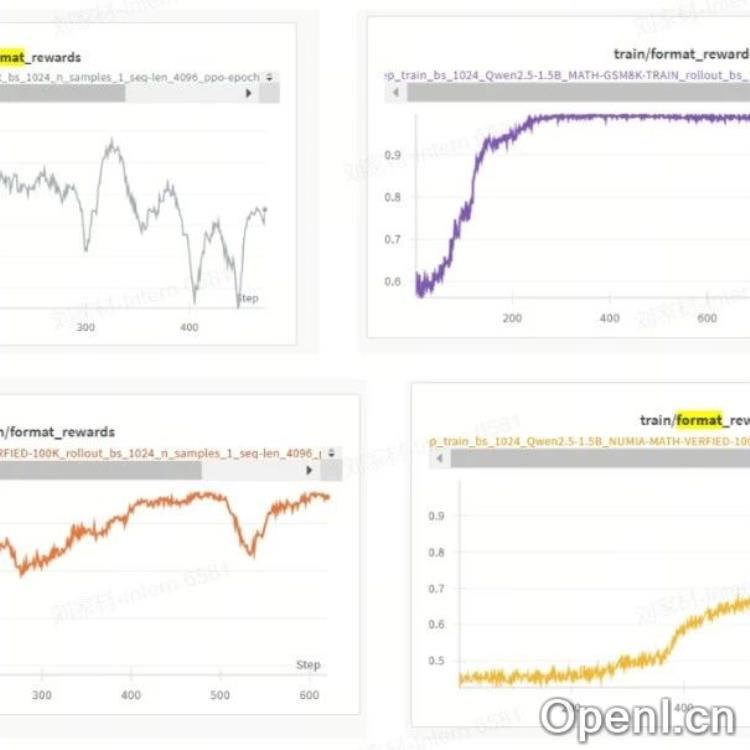
作者进行了四个实验,分别使用不同的数据集和奖励函数:
- 实验一: 数据集:MATH TRAIN + GSM8K TRAIN 15K;奖励函数:准确性奖励 (accuracy_reward)。
- 实验二: 数据集:MATH TRAIN + GSM8K TRAIN 15K;奖励函数:准确性奖励 + 格式奖励 (accuracy_reward + format_reward)。
- 实验三: 数据集:NUMIA-MATH 100K;奖励函数:准确性奖励。
- 实验四: 数据集:NUMIA-MATH 100K;奖励函数:准确性奖励 + 格式奖励。
算法采用策略梯度 (policy gradient),优势估计使用 REINFORCE + 全局批量归一化 (global batch normalization)。prompt模板与DeepSeek R1相同,使用math_verify进行答案抽取和匹配。
2. 实验结果
实验结果显示,在简单数据集 (MATH-GSM8K TRAIN 15K) 上,添加格式奖励可以加快模型学习速度,但对最终准确率提升有限。在复杂数据集 (NUMIA-MATH 100K) 上,添加格式奖励反而导致模型性能下降,模型倾向于通过满足格式要求来获得奖励,而不是真正解决问题。
- 简单数据集 (MATH-GSM8K 15K):实验一和实验二在训练集和测试集上都取得了显著的提升,但实验二的测试集结果数据丢失。
- 复杂数据集 (NUMIA-MATH 100K):实验三在测试集上取得了显著的提升,而实验四的测试集结果却大幅下降。
3. 关键现象与结论
实验中观察到以下几个有趣的现象:
- 格式奖励易学: 添加格式奖励后,模型快速学习了指定的格式要求,尤其是在复杂数据集上。
- 复杂数据集上格式奖励易被“滥用”: 在复杂数据集上,模型更容易通过满足格式要求来获得奖励,而忽略了问题的实际解答,导致模型性能下降。
- 准确率与响应长度正相关 (复杂数据集): 在复杂数据集上,准确率提升与响应长度增加呈正相关,这在简单数据集上并不明显。
- 缺乏“Aha Moment”: 模型在训练过程中并未出现明显的“顿悟”现象,模型中本身就存在一定的“反思”能力。
- 探索与利用的平衡: 模型训练过程中熵快速收敛,需要改进方法来平衡探索与利用。
作者总结,一个好的奖励函数应该先保证准确性奖励,再考虑添加格式奖励;同时,需要研究如何更好地平衡探索与利用,以提高模型的训练效率和性能。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。