全方位理解多模态模型CoT能力
原标题:DeepSeek、OpenAI、Kimi视觉推理到底哪家强?港中文MMLab推出推理基准MME-COT
文章来源:量子位
内容字数:6742字
港中文MMLab提出MME-CoT:全面评估大型多模态模型视觉推理能力
本文总结了港中文MMLab研究者提出的MME-CoT基准测试,该基准旨在全面评估大型多模态模型(LMMs)的视觉推理能力。MME-CoT超越了以往仅评估最终答案正确性的方法,细粒度地评估了视觉链式思维(CoT)的质量、鲁棒性和效率。
1. MME-CoT的创新之处
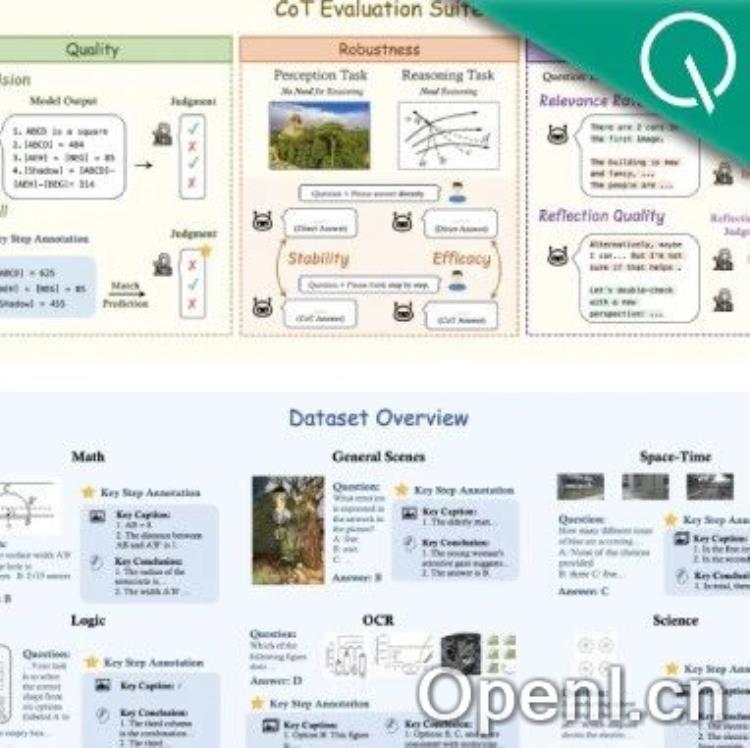
与以往LMM基准测试不同,MME-CoT提出了一个严格的多方面评估框架,着重研究视觉CoT的不同方面。它包含数学、科学、OCR、逻辑、时空和通用场景六大领域,涵盖17个子类,共包含1130个精选问题和3865个关键步骤标注。MME-CoT区分了感知任务和推理任务,避免了以往基准测试中两类任务混淆的问题。
2. 细粒度的评估指标
MME-CoT设计了三个评估方向,分别回答三个关键问题:
- CoT的质量: 使用召回率(Recall)和精确率(Precision)两个指标评估CoT步骤的有用性和准确性,避免了模型通过错误逻辑得到正确答案的夸大现象。GPT-4被用来辅助评估。
- CoT的鲁棒性: 通过比较感知任务和推理任务在直接回答和CoT回答两种Prompt下的表现,评估CoT对不同任务类型的稳定性(Stability)和有效性(Efficacy),考察CoT是否会对感知任务产生负面影响。
- CoT的效率: 使用相关比例(Relevance Rate)和反思质量(Reflection Quality)两个指标评估CoT的推理效率,考察长CoT中步骤的相关性和反思步骤的有效性。
3. 实验结果与结论
研究者们在MME-CoT上测试了13个现有的LMM和两个最新的LLM (DeepSeek-R1和o3-mini)。实验结果显示:
- CoT质量:Kimi k1.5 > DeepSeek-R1 >> o3-mini
- CoT鲁棒性:o3-mini > Kimi k1.5 > DeepSeek-R1
- CoT效率:o3-mini > Kimi k1.5 > DeepSeek-R1
此外,研究还发现:
- 长CoT并不一定包含所有关键步骤,模型有时会跳过中间步骤得出正确答案。
- 更大的模型参数量通常能更好地掌握推理能力。
- 模型的反思错误类型多样,包括无效反思、不完整、重复和干扰等。
4. MME-CoT的意义
MME-CoT为评估LMM的视觉推理能力提供了一个系统化的基准,指明了该领域的关键发展方向。它揭示了现有模型在推理质量、鲁棒性和计算效率方面的不足,为后续研究奠定了重要基础,将推动LMM实现更强大、更可靠的视觉推理能力。
联系作者
文章来源:量子位
作者微信:
作者简介:追踪人工智能新趋势,关注科技行业新突破
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。