原标题:CLaMP 3:AI音乐检索新突破,跨模态跨语言精准匹配
文章来源:小夏聊AIGC
内容字数:6748字
AI赋能音乐检索:CLaMP 3开启跨模态、跨语言新时代
想象一下,你向人工智能展示一张充满异域风情的沙漠景象,它立刻就能识别出《星球大战》的经典配乐;或者你提供一幅欧洲宫廷绘画,它便能精准匹配巴洛克时期的音乐作品。这不再是遥不可及的幻想,得益于音乐信息检索(MIR)领域的最新突破,由音乐学院、清华大学、香港科技大学及上海纽约大学等机构的研究者联合研发的CLaMP 3框架,正将这一愿景变为现实。
突破传统MIR的局限
传统的音乐信息检索系统常常受限于单一模态数据的处理能力,例如只能处理文本与音频、或文本与乐谱的组合。此外,大部分现有数据集以英语为主,缺乏对其他语言的充分覆盖,导致这些系统在全球音乐语境下的应用受到极大限制。CLaMP 3的出现,正是为了解决这些瓶颈问题。
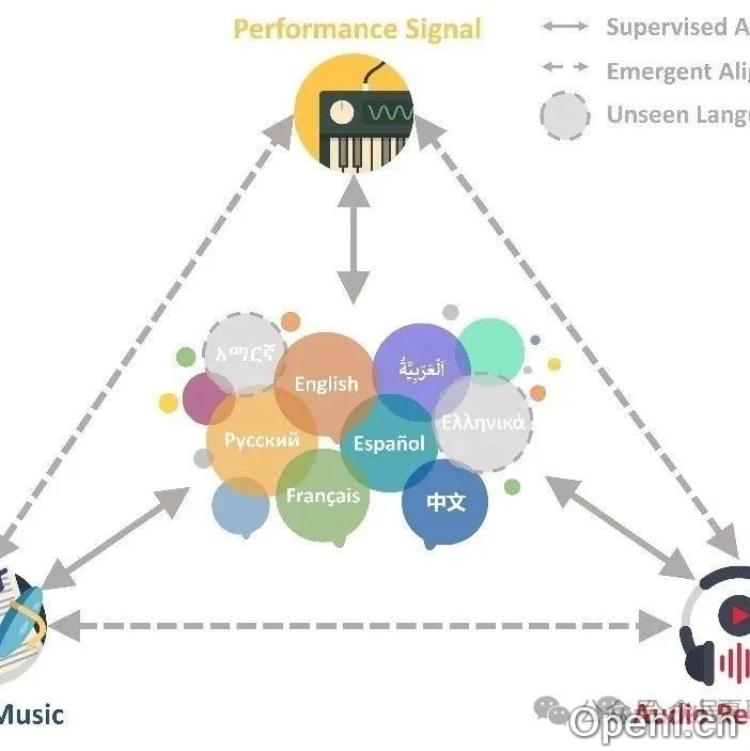
CLaMP 3:跨模态、跨语言的统一框架
CLaMP 3 (Contrastive Language-Music Pre-training)是一个具有里程碑意义的跨模态、跨语言统一音乐信息检索框架。它巧妙地利用对比学习方法,首次实现了乐谱、演奏信号、音频录音等多种音乐模态与多语言文本的联合对齐。这意味着不同模态的音乐数据可以借助文本桥接进行高效检索,突破了传统方法的局限。
更令人瞩目的是,CLaMP 3的多语言文本编码器具备强大的泛化能力,能够有效处理前所未见的语言,在跨语言检索任务中展现出卓越的性能。这为全球范围内的音乐信息检索带来了前所未有的可能性。
大规模数据集与创新技术
CLaMP 3的成功离不开其背后庞大而高质量的数据集支持。研究团队构建了规模高达2.31M的音乐-文本对的M4-RAG数据集,并结合详细的音乐元数据,涵盖了27种语言、194个国家的音乐文化。此外,他们还推出了WikiMT-X基准数据集,进一步推动跨模态音乐理解的研究。
在技术层面,CLaMP 3 采用对比学习和检索增强生成(RAG)策略,构建统一的音乐表示空间。通过多阶段训练,它实现了不同模态的精准对齐,并有效避免了模态漂移问题。其核心组件——多模态Transformer编码器,能够高效处理乐谱、音频和多语言文本数据。
卓越的实验结果
实验结果表明,CLaMP 3在多个MIR任务上都取得了当前最佳性能(SOTA),显著超越了现有的基线模型。尤其是在跨模态和跨语言检索任务中,其泛化能力令人印象深刻,即使面对训练集中未曾出现过的语言,也能保持优秀的检索精度。
未来展望:迈向更智能的音乐检索
CLaMP 3的成功标志着音乐信息检索技术迈入了新的时代。未来,随着技术的不断发展和数据集的持续完善,我们有理由相信,AI将能够更精准、更全面地理解和检索全球范围内的音乐信息,为音乐创作、研究和欣赏带来性的变化。这将不仅促进音乐文化的交流与融合,也将为音乐产业带来新的机遇。
联系作者
文章来源:小夏聊AIGC
作者微信:
作者简介:专注于人工智能生成内容的前沿信息与技术分享。我们提供AI生成艺术、文本、音乐、视频等领域的最新动态与应用案例。每日新闻速递、技术解读、行业分析、专家观点和创意展示。期待与您一起探索AI的无限潜力。欢迎关注并分享您的AI作品或宝贵意见。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。