













X-CLIP (base-sized model)
X-CLIP model (base-sized, patch resolution of 16) trained on Kinetics-400. It was introduced in the paper Expanding Language-Image Pretrained Models for General Video Recognition by Ni et al. and first released in this repository.
This model was trained using 32 frames per video, at a resolution of 224×224.
Disclaimer: The team releasing X-CLIP did not write a model card for this model so this model card has been written by the Hugging Face team.
Model description
X-CLIP is a minimal extension of CLIP for general video-language understanding. The model is trained in a contrastive way on (video, text) pairs.
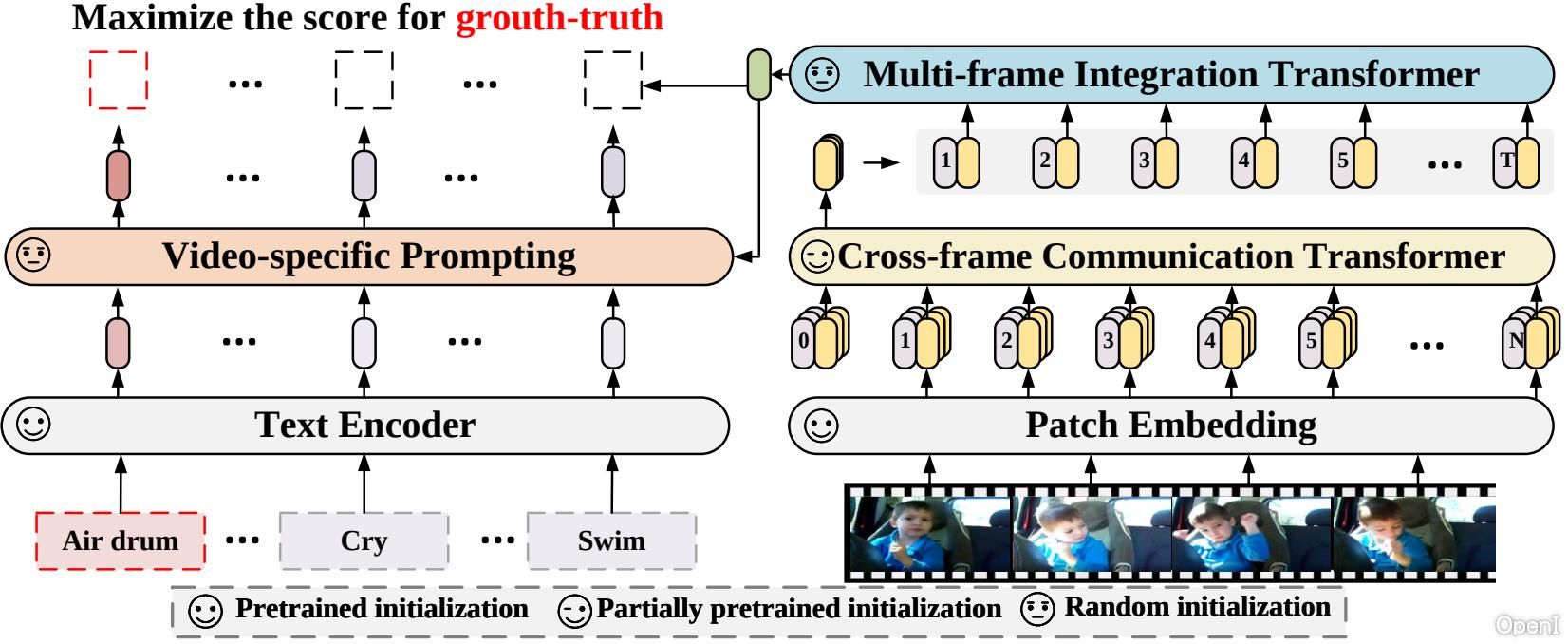
This allows the model to be used for tasks like zero-shot, few-shot or fully supervised video classification and video-text retrieval.
Intended uses & limitations
You can use the raw model for determining how well text goes with a given video. See the model hub to look for
fine-tuned versions on a task that interests you.
How to use
For code examples, we refer to the documentation.
Training data
This model was trained on Kinetics 400.
Preprocessing
The exact details of preprocessing during training can be found here.
The exact details of preprocessing during validation can be found here.
During validation, one resizes the shorter edge of each frame, after which center cropping is performed to a fixed-size resolution (like 224×224). Next, frames are normalized across the RGB channels with the ImageNet mean and standard deviation.
Evaluation results
This model achieves a zero-shot top-1 accuracy of 44.6% on HMDB-51, 72.0% on UCF-101 and 65.2% on Kinetics-600.
数据评估
本站OpenI提供的microsoft/xclip-base-patch16-zero-shot都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由OpenI实际控制,在2023年 6月 6日 下午2:57收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,OpenI不承担任何责任。
相关导航







全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。