一文带你理解现在推理大模型,以及DeepSeek R1的技术实现
原标题:一文理解推理大模型-Understanding Reasoning LLMs
文章来源:智猩猩GenAI
内容字数:9850字
理解推理大型语言模型
本文概述了Sebastian Raschka关于理解推理大型语言模型(LLMs)的博客文章。文章探讨了推理模型的定义、优缺点,以及构建和改进它们的四种主要方法。文章还介绍了DeepSeek R1的训练方法,并分享了在低成本下训练推理模型的技巧。
1. 何谓“推理模型”?
文章首先澄清了“推理模型”这一模糊概念。作者将其定义为能够回答需要复杂、多步骤生成并包含中间步骤的问题的模型。例如,“如果一列火车以每小时60英里的速度行驶3小时,它能走多远?”就需要推理能力。与之相对,“法国的首都是哪里?”则只需事实检索。
大多数LLMs都具备基本的推理能力,但“推理模型”通常指在更复杂的推理任务(如解决谜题、谜语和数学证明)中表现出色的LLMs。这些模型通常会在回答中显示其“思考”过程,这可以通过明确包含在回复中或通过多个内部迭代实现。
2. 何时使用推理模型?
推理模型擅长解决复杂任务,例如解决谜题、高级数学问题和具有挑战性的编程任务。然而,对于简单的任务(如摘要、翻译或基于知识的问题回答),使用推理模型则效率低下且成本高昂。文章强调需要根据任务选择合适的工具或LLM。
3. DeepSeek 训练流程概述
文章概述了DeepSeek发布的三个不同模型变体:DeepSeek-R1-Zero、DeepSeek-R1和DeepSeek-R1-Distill。DeepSeek-R1-Zero采用纯强化学习(RL)训练,无需监督微调(SFT);DeepSeek-R1则在DeepSeek-V3基础上,先进行SFT,再进行RL训练;DeepSeek-R1-Distill则通过蒸馏技术,在SFT数据上微调Qwen和Llama模型。
4. 四种构建和改进推理模型的方法
文章总结了四种增强LLMs推理能力的关键技术:
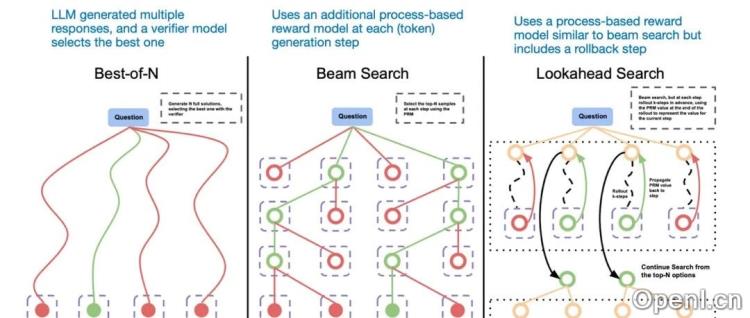
- 推理时间扩展:在推理时增加计算资源以提高输出质量,例如使用思维链(CoT)提示或投票和搜索策略。
- 纯强化学习:DeepSeek R1-Zero证明了仅使用RL即可训练出具备推理能力的模型,其奖励机制包括准确性和格式奖励。
- 监督微调和强化学习:这是目前构建高性能推理模型的主要方法,DeepSeek R1即采用了这种方法。
- 纯监督微调(SFT)和蒸馏:通过在大型LLMs生成的SFT数据集上微调较小的LLMs,可以创建更高效、成本更低的模型。
5. 对DeepSeek R1的思考
文章认为DeepSeek R1是一个了不起的工作,其开源和高效性使其成为OpenAI的o1的一个有趣替代品。但直接比较两者存在难度,因为OpenAI没有公开o1的许多细节。
6. 在小成本下训练推理模型
文章指出,训练DeepSeek R1级别的模型成本高昂,但模型蒸馏提供了一种更具成本效益的替代方案。文章还介绍了Sky-T1和TinyZero两个项目,分别展示了在低成本下通过SFT和纯RL训练推理模型的可行性。
7. 总结
文章总结了当前推理模型领域的前沿技术,并展望了未来发展方向,例如“旅程学习”方法,该方法通过让模型学习错误的解决路径来提高模型的推理能力和鲁棒性。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。