Migician – 北交大联合清华、华中科大推出的多模态视觉定位模型
Migician是什么
Migician是由北京交通大学、华中科技大学和清华大学的研究团队联合开发的多模态大语言模型(MLLM),旨在应对形式的多图像定位(Multi-Image Grounding,MIG)任务。该模型基于大规模训练数据集MGrounding-630k,能够根据不同形式的查询(如文本描述、图像或两者结合)在多幅图像中识别并精确定位相关视觉区域。Migician通过两阶段训练方法,结合了多图像理解和单图像定位的能力,实现在复杂视觉场景中的高效应用,推动了多模态模型在细粒度视觉定位方面的进展。
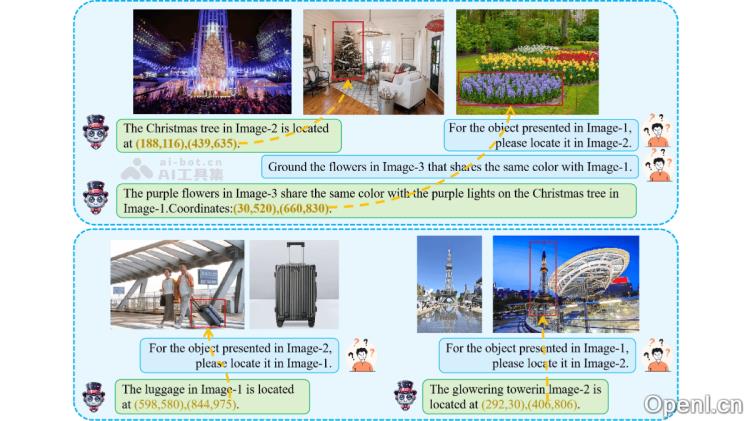
Migician的主要功能
- 跨图像定位:在多幅图像中精确查找与查询相关的对象或区域,并提供其确切位置(如坐标框)。
- 灵活的输入形式:支持多种查询方式,包括文本、图像或两者的组合,比如“在图2中找出颜色不同但与图1相似的物体”。
- 多任务支持:能够处理多种与多图像相关的任务,包括对象跟踪、差异识别和共同对象定位等。
- 高效推理:利用端到端的模型设计,直接在多图像场景中进行推理,避免了传统方法中多步骤推理带来的复杂性和错误传播问题。
Migician的技术原理
- 端到端的多图像定位框架:采用端到端的架构直接处理多图像定位任务,省去任务分解为多个子任务的复杂性和效率问题,能够根据查询直接输出目标对象的位置。
- 大规模指令调优数据集(MGrounding-630k):包含超过63万条多图像定位任务的数据,涵盖多种任务类型(如静态差异定位、共同对象定位和对象跟踪等),结合形式的指令,使模型学习到多样化的定位能力。
- 两阶段训练方法:
- 第一阶段:在多种多图像任务上进行训练,学习基本的多图像理解和定位能力。
- 第二阶段:通过形式的指令调优,提升模型在复杂查询下的定位能力,确保适应多样化任务。
- 多模态融合与推理:结合视觉和语言模态的信息,通过多模态融合实现对复杂查询的理解与定位,处理抽象的视觉语义信息,例如通过对比、相似性或功能关联来定位目标对象。
- 模型合并技术:采用模型合并技术,平均不同训练阶段的权重,以优化整体性能。
Migician的项目地址
- 项目官网:https://migician-vg.github.io/
- GitHub仓库:https://github.com/thunlp/Migician
- HuggingFace模型库:https://huggingface.co/Michael4933/Migician
- arXiv技术论文:https://arxiv.org/pdf/2501.05767
Migician的应用场景
- 自动驾驶:快速识别车辆周围的目标(如行人、障碍物),支持多视角感知与动态目标跟踪。
- 安防监控:通过多摄像头联动识别异常行为或目标,分析人群聚集、快速移动等异常情况。
- 机器人交互:精准定位目标物体,支持机器人在复杂环境中执行抓取、导航等任务。
- 图像编辑:分析多幅图像内容,实现对象替换、删除或创造性内容生成。
- 医疗影像:融合多模态影像,迅速定位病变区域或异常组织,支持动态监测。
常见问题
- Migician支持哪些类型的查询? Migician支持文本描述、图像或两者结合的形式查询。
- 如何获取Migician的模型? 您可以通过其项目官网、GitHub仓库或HuggingFace模型库下载模型。
- Migician适用于哪些行业? Migician广泛应用于自动驾驶、安防监控、机器人交互、图像编辑和医疗影像等多个领域。
- 如何提升模型的定位精度? 通过提供清晰、具体的查询指令,可以有效提升模型的定位精度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。